


راهنمای جامع پرامپتنویسی برای مدلهای ویدیویی AI؛ از حرکت دوربین تا کنترل سینمایی صحنه
اگر تجربهی کار با مدلهای زبانی (LLM) مثل Claude یا ChatGPT را دارید، احتمالاً تصور میکنید پرامپتنویسی برای مدلهای ویدیویی هم همان منطق را دارد. اما در واقعیت، فضای پرامپتنویسی برای مدلهایی مثل Seedance 2.0، Kling 3.0، و Google Veo 3 یک دنیای کاملاً متفاوت است. اینجا دیگر صرفاً با کلمات سروکار ندارید. با زمان، دوربین، نور، حرکت، و فیزیک سروکار دارید. اینجا دیگر یک نویسنده نیستید بلکه یک کارگردان، فیلمبردار و تدوینگر همزمان هستید.
خبر خوب این است که این مهارت کاملاً قابل یادگیری است. مدلهای ویدیویی نسل جدید، گرامرهای مشخصی دارند و وقتی این گرامرها را بشناسید، میتوانید با اطمینان بسیار بالاتری به نتیجهی دلخواه برسید. خبر بهتر این است که در این مقاله، یک کلاس درس کامل را برایتان آماده کردهایم. از مفاهیم پایه تا تکنیکهای پیشرفتهای مثل JSON Prompting و Timeline Prompting. همه را با مثالهای واقعی و قابل کپی پوشش میدهیم.
هدف نهایی این است: در پایان مقاله، شما باید بتوانید یک پرامپت ویدیویی حرفهای بنویسید که در عرض چند ثانیه، خروجی سینمایی بهسبک استودیوهای حرفهای تولید کند. پس بریم سراغ موضوع اما اول، باید بفهمیم چرا پرامپت ویدیو با پرامپت تصویر و LLM بهکلی متفاوت است. پیشنهاد میکنم مقاله پرامپت نویسی برای Claude را هم مشاهده کنید.

سه تفاوت بنیادی پرامپت ویدیو با تصویر و LLM
درک این تفاوتها، نقطهی شروع همهچیز است. بسیاری از کاربرانی که از فضای ChatGPT یا Midjourney به ویدیو میآیند، با همان منطق قبلی پرامپت مینویسند و خروجیهای ضعیف میگیرند، بدون اینکه بفهمند چرا. در این بخش، سه تفاوت بنیادی را بررسی میکنیم که فهم آنها ذهنیت شما را بهکلی تغییر میدهد.
تفاوت ۱: عنصر زمان و توالی
در یک پرامپت تصویر، شما یک «لحظهی یخزده» را توصیف میکنید. یک قاب ثابت که تمام عناصر آن همزمان وجود دارند. اما در ویدیو، شما یک بازهی زمانی را توصیف میکنید که در آن عناصر تغییر میکنند، حرکت میکنند، ظاهر و ناپدید میشوند. این تفاوت بنیادی، نحوهی فکر کردن شما را عوض میکند: بهجای فکر کردن به «این صحنه چه چیزهایی دارد؟»، باید فکر کنید به «در این ۵ ثانیه، چه اتفاقی میافتد؟».
این تفاوت در ابزارهایی مثل Seedance 2.0 با ظهور تکنیکی بهنام Timeline Prompting به اوج خود میرسد تکنیکی که در آن شما هر ثانیه از ویدیو را با یک تایماستمپ مشخص توصیف میکنید. این موضوع را در بخشهای بعدی بهتفصیل بررسی میکنیم.
تفاوت ۲: حرکت دوربین بهعنوان شخصیت دوم در هوش مصنوعی
در یک پرامپت تصویر، دوربین فقط زاویهی دید است: «نمای نزدیک از یک گل». اما در ویدیو، دوربین خودش یک بازیگر فعال است که میتواند حرکت کند، چرخش کند، تعقیب کند، نزدیک شود، و دور شود. در حقیقت، حرکت دوربین میتواند احساس صحنه را بهکلی عوض کند. همان صحنه با یک slow dolly-in، احساس تنشی متفاوت از همان صحنه با یک wide static shot دارد.
این یعنی هر پرامپت ویدیویی حرفهای، باید یک بخش جداگانه برای Camera System داشته باشد. این بخش بهقدری مهم است که در راهنمای رسمی Seedance 2.0، یکی از قواعد طلایی این است که: «حرکت دوربین را از حرکت سوژه جدا کنید». مخلوط کردن این دو، یکی از رایجترین دلایل لرزش و jitter و همینطور artifact در ویدیوهای تولیدشده است.
تفاوت ۳: پایداری شخصیت و فیزیک
در تصویر، شخصیت در یک قاب ثابت است. اما در ویدیو، شخصیت باید در طول ۵، ۱۰ یا ۱۵ ثانیه «همان شخصیت» بماند. همان چهره، همان لباس، همان رنگ مو. این چالش بهنام character consistency یا «پایداری شخصیت» یکی از سختترین مسائل در تولید ویدیو با AI است. مدلهای نسل جدید مثل Kling 3.0 و Seedance 2.0 پیشرفت چشمگیری در این زمینه داشتهاند، اما هنوز هم پرامپت شما باید این پایداری را بهصراحت درخواست کند.
علاوه بر پایداری شخصیت، عنصر فیزیک هم وارد میشود: گرانش، اینرسی، تماس بین اشیاء، نفوذ نور. وقتی پرامپت مینویسید «یک سکه از روی میز میافتد»، مدل باید بفهمد سکه باید با گرانش پایین برود، نه افقی. مدلهای جدید این فیزیک را تا حدی شبیهسازی میکنند، اما اگر در پرامپت خود به فیزیک اشاره نکنید، اغلب نتیجهی نامطلوب میگیرید. مثلاً بهجای «راه میرود»، بنویسید:
«heel-first walking with realistic weight transfer» تا مدل بهجای شناور بودن پاها، تماس واقعی با زمین را شبیهسازی کند.
حالا که سه تفاوت بنیادی روشن شد، آمادهایم وارد فاز عملی شویم. در بخش بعدی، ساختار ششبخشی پرامپت ویدیویی را معرفی میکنیم. همان ساختاری که در راهنماهای رسمی Veo3، Seedance و Kling تکرار شده است. این ساختار، اسکلت اصلی هر پرامپت حرفهای است و یادگیری آن، اولین گام برای کنترل واقعی روی خروجی مدلهای ویدیویی به شمار میآید.

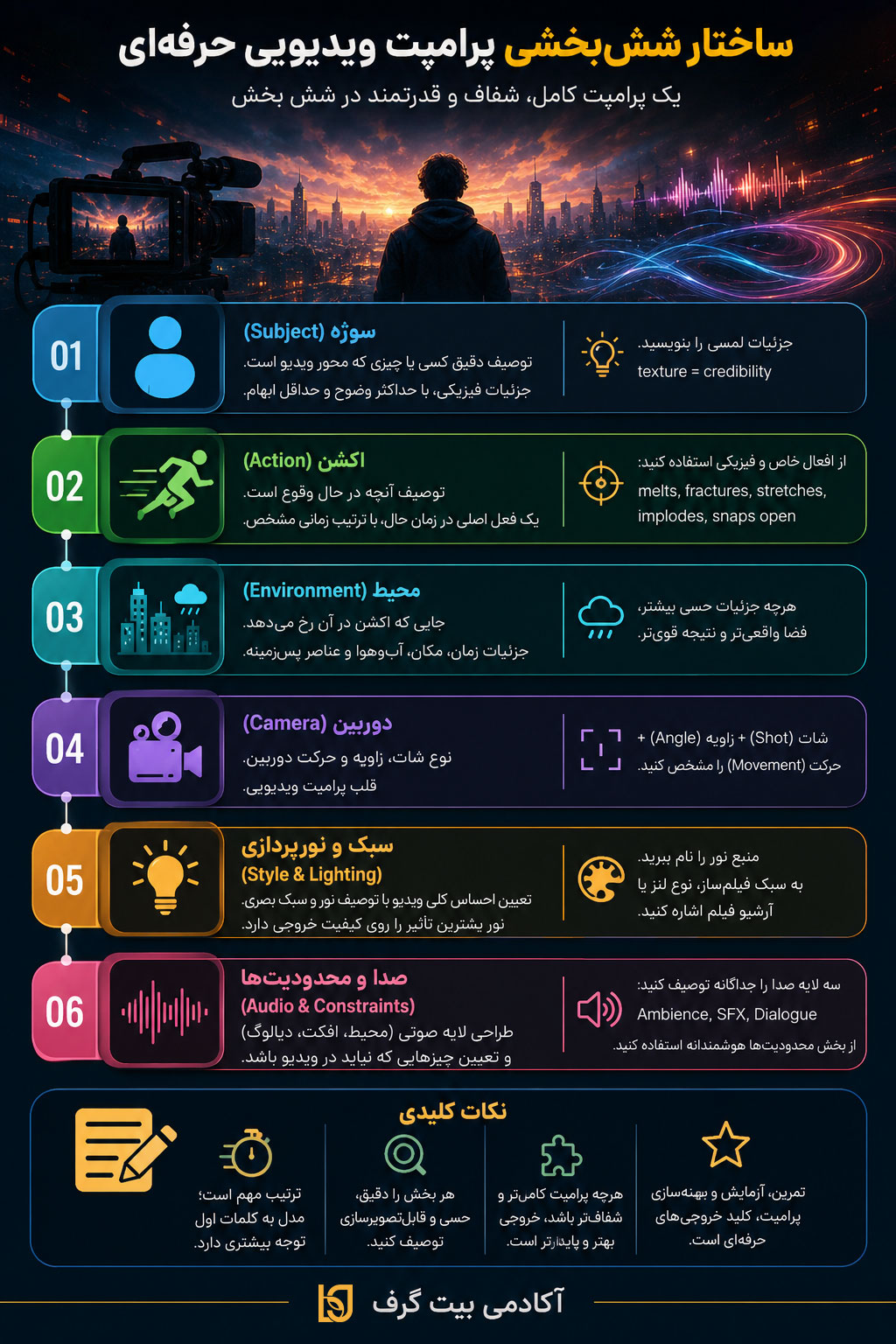
ساختار ششبخشی پرامپت ویدیویی حرفهای
بعد از سالها تجربه و آزمایش روی هزاران پرامپت، اکثر مدلهای پیشرفتهی ویدیویی به یک ساختار مشابه همگرا شدهاند. این ساختار، با اندکی تفاوت، در راهنماهای رسمی Google DeepMind، Seedance، و Kling تکرار شده است. درک این ساختار، اولین گام برای پرامپتنویسی حرفهای است. اگر فقط یک چیز از این مقاله را به یاد بسپارید، باید همین باشد.
شش بخش اصلی هر پرامپت ویدیویی به این صورتاند:
- سوژه
- اکشن
- محیط
- دوربین
- سبک و نور
- صدا و محدودیتها
ترتیب این بخشها مهم است، مدل اولین کلمات را با توجه بیشتری پردازش میکند. همین حالا این بخش را یادداشت کنید.
بخش ۱: سوژه (Subject)
سوژه یعنی چه کسی یا چه چیزی محور ویدیو است. اینجا باید با حداکثر ویژگی فیزیکی و حداقل ابهام توصیف کنید. بهجای «یک مرد»، بنویسید «یک مرد جوان حدود ۲۸ ساله، با موهای فرفری بلوند، پوست روشن، چشمان آبی روشن، هودی مشکی». این جزئیات از دو نظر مهماند: اول اینکه ویدیوی شما را خاص و قابلپیشبینی میکند، و دوم اینکه برای پایداری شخصیت بین فریمها (character consistency) ضروریاند.
نکتهی پیشرفته:
توصیفهای لمسی (tactile) از توصیفهای انتزاعی قویتر کار میکنند. بهجای «موهای زیبا»، بنویسید «موهای فر بلوند که در دستههای گرد نرم جمع میشوند». این نوع توصیف، در راهنمای رسمی Kling 3.0 با عنوان «texture = credibility» مطرح شده است. پس جزئیات لمسی، خروجی را واقعیتر میکند.
بخش ۲: اکشن (Action)
اکشن یعنی چه کاری در حال وقوع است. در پرامپت ویدیو، باید یک فعل اصلی در زمان حال داشته باشید، نه چند فعل همزمان. بهجای «مرد در حال راه رفتن، نگاه کردن، و گفتن چیزی است»، یکی را انتخاب کنید: «مرد آرام در حال راه رفتن به سمت دوربین است». اگر چند اکشن لازم دارید، آنها را به ترتیب زمانی بنویسید، مثل یک سناریو.
یک تکنیک قدرتمند، استفاده از افعال خاص به جای افعال عمومی است. در راهنمای رسمی Veo3.1 توصیه شده که بهجای «becomes»، از افعال صریح مثل «melts», «fractures», «stretches», «implodes», «snaps open» استفاده کنید. این افعال، فیزیک خاصی را به مدل القا میکنند که خروجی واقعیتر تولید میشود. همینجا مجدد عذرخواهی میکنم که بعضی اوقات خبری از ترجمه به فارسی نیست. این کلمات و وزن آن ها بسیار مهم است که به همین صورت یاد بگیرید. در نهایت شما در یک پروژه رسمی پرامپت انگلیسی می نویسید. الان بهترین فرصت برای یادگیری است.
بخش ۳: محیط (Environment)
محیط جایی است که اکشن در آن رخ میدهد. اینجا هم مثل سوژه، جزئیات حسی مهم است: زمان روز، فصل، آبوهوا، ویژگیهای مکان، اشیای پسزمینه. بهجای «در یک خیابان»، بنویسید «در یک خیابان نئوندار توکیو در شب بارانی، با انعکاس چراغهای نئون روی آسفالت خیس». این سطح از جزئیات، به مدل کمک میکند فضا را با تمام لایههایش بسازد.
بخش ۴: دوربین (Camera)
این بخش قلب پرامپت ویدیویی است. باید سه چیز را مشخص کنید: نوع شات (shot type) مثل close-up یا wide shot؛ زاویه (angle) مثل eye-level یا low angle؛ و نوع حرکت (movement) مثل dolly یا tracking. در ادامهی مقاله یک بخش کامل به این موضوع اختصاص دادهایم، چون آنقدر حیاتی است که جای جداگانه میخواهد.
بخش ۵: سبک و نورپردازی (Style & Lighting)
سبک و نور، احساس کلی ویدیو را میسازند. در راهنمای رسمی Seedance 2.0 تأکید شده که توصیف نور بیشترین تأثیر را روی کیفیت خروجی دارد. حتی بیشتر از همهی صفتهای دیگر. بهجای «نور دراماتیک»، نام منبع نور را ذکر کنید: «نور غروب طلایی از پنجرهی سمت راست»، «نئونهای صورتی و آبی»، «نور شمعی گرم از سمت چپ کادر».
برای سبک، میتوانید از سه منبع الهام استفاده کنید: اشاره به فیلمساز مثل «به سبک Wes Anderson» یا «در حالوهوای Christopher Nolan»؛ اشاره به نوع لنز مثل «لنز anamorphic 35mm با flare افقی»؛ یا اشاره به آرشیو فیلم مثل «در سبک film noir دههی ۱۹۵۰» یا «جسارت بصری دههی ۸۰».
بخش ۶: صدا و محدودیتها (Audio & Constraints)
در مدلهای جدیدی که صدا تولید میکنند (Veo3، Kling 3.0 و هم اکنون Seedance2.0) باید لایهی صوتی را هم طراحی کنید. این لایه شامل سه عنصر است: ambience یا صدای محیط، SFX یا افکتهای نقطهای، و در صورت نیاز dialogue یا گفتوگو. هر کدام را در یک جملهی جدا توصیف کنید تا مدل با آنها قاطی نشود.
بخش محدودیتها (constraints) جایی است که میگویید چه چیزی نباید در ویدیو وجود داشته باشد. این یکی از قدرتمندترین تکنیکهای پرامپت ویدیویی است که در ادامهی مقاله بهتفصیل بررسی میکنیم.
مثال یک پرامپت کامل با ساختار ۶-بخشی:
- [سوژه] یک مرد جوان با موهای فرفری بلوند، هودی مشکی، و چشمان خستهی آبی
- [اکشن] آرام پشت میز در حال کدنویسی؛ بهتدریج از سمت دوربین چرخیده و به سمت در میرود
- [محیط] اتاق خواب دنج شب با حالوهوای دههی ۸۰، پوسترهای رنگی روی دیوار، چراغ مطالعهی گرم
- [دوربین] medium shot از پشت سر، slow dolly forward بدون جیتر
- [سبک] کیفیت سینمایی Pixar، 8K، global illumination نرم، عمق میدان کم
- [صدا] ambient: تایپ کیبرد و وزش باد ضعیف؛ SFX: صدای نامشخص از کمد در ثانیهی ۴؛ no dialogue
حرکت دوربین در پرامپت ویدیو؛ قلب کار
اگر یک عنصر در پرامپت ویدیو وجود داشته باشد که ویدیوی شما را از «قابلقبول» به «حرفهای» ببرد، آن عنصر حرکت دوربین در پرامپت ویدیو است. در یک بررسی میدانی Atlas Cloud، حرکت دوربین بهعنوان «بیشترین عنصر دستنخورده در پرامپتهای اکثر کاربران» شناسایی شده است. اضافه کردن یک جملهی دقیق دربارهی حرکت دوربین، اغلب بیشتر از اضافه کردن ۱۰ صفت توصیفی، کیفیت ویدیو را بالا میبرد.
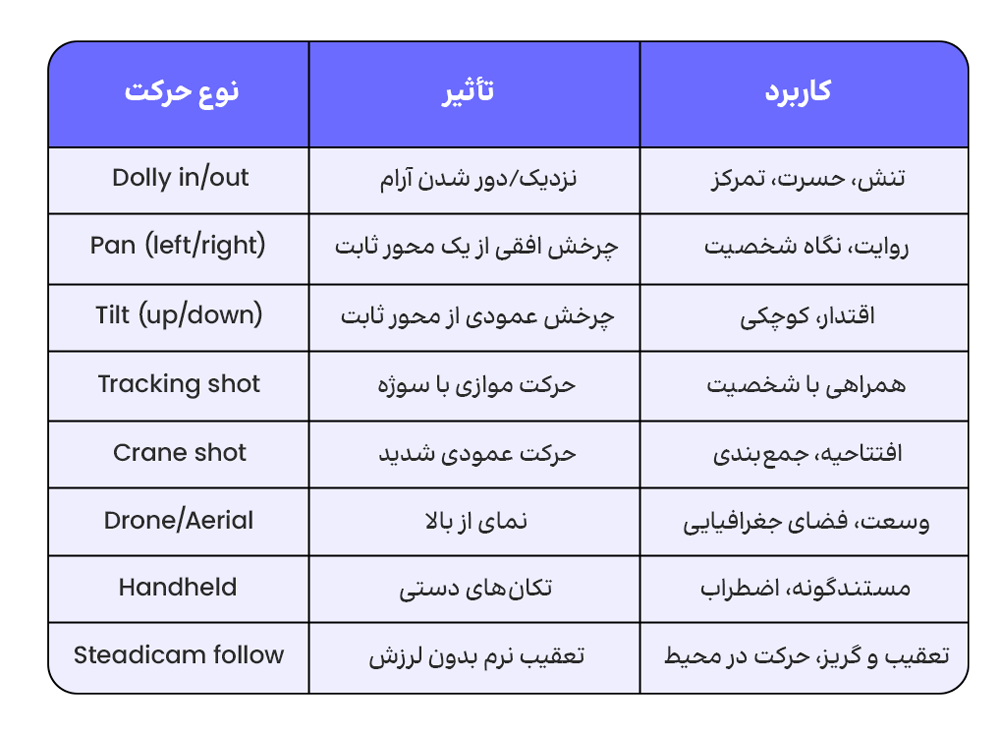
هشت نوع حرکت دوربین برای هوش مصنوعی که باید بشناسید
این هشت نوع، کلمات کلیدی هستند که مدلهای Veo3، Seedance و Kling بهخوبی تشخیص میدهند چون روی محتوای واقعی فیلمسازی آموزش دیدهاند. استفاده از این واژگان حرفهای بهجای توصیفهای آماتور («دوربین به سمت او میرود»)، تفاوت چشمگیری در خروجی ایجاد میکند.
سه قاعدهی طلایی حرکت دوربین
قاعدهی اول: یک حرکت اصلی در هر کلیپ. اگر در یک پرامپت بنویسید «دوربین در حال chain shot است، چرخش ۳۶۰ درجه دارد، و سوژه به سمت دوربین میدود»، در ۹۹ درصد موارد، خروجی unstable و لرزان خواهد بود. هر کلیپ ۵-۱۵ ثانیهای، یک حرکت اصلی دوربین را خوب اجرا میکند، نه بیشتر. اگر چند حرکت میخواهید، از تکنیک multi-shot prompting استفاده کنید (که در ادامه بررسی میکنیم).
قاعدهی دوم: جدا کردن حرکت دوربین از حرکت سوژه. این یکی از مهمترین قواعدی است که در راهنمای رسمی Seedance 2.0 با تأکید آمده است. بهجای «دوربین میچرخد دور یک رقصندهی در حال رقصیدن»، بنویسید «رقصنده آرام میچرخد. دوربین قاب ثابت دارد». این جداسازی، به مدل کمک میکند هر دو حرکت را بهدرستی محاسبه کند.
قاعدهی سوم: کلمات سرعتگرا با احتیاط. کلمهی «fast» یکی از خطرناکترین کلمات در پرامپت ویدیویی است. ترکیب «حرکت سریع دوربین + برشهای سریع + صحنهی شلوغ» تقریباً همیشه به جیتر و artifact منجر میشود. اگر تمپوی سریع میخواهید، فقط یکی از این عناصر را سریع کنید، نه همه را. بهجای «fast»، میتوانید از کلمات کنترلشدهتر مثل «smooth», «quick but stable», یا «accelerated but smooth» استفاده کنید.
کلمهی هشدار:
کلمهی «fast» در پرامپت Seedance بیش از ۸۰ درصد موارد باعث افت کیفیت میشود. در راهنمای رسمی این مدل، صراحتاً توصیه شده که از کلمات تمپو مثل «slow», «smooth», «gentle» استفاده کنید و فقط در صورت لزوم به سراغ «quick» یا «brisk» بروید هرگز از «fast» در ترکیب با چند عنصر دیگر استفاده نکنید.
پرامپت نویسی برای کلیپهای پیچیدهتر
اگر میخواهید در یک ویدیوی ۱۵ ثانیهای چند شات داشته باشید، تکنیک multi-shot prompting را به کار بگیرید. این تکنیک، هر شات را بهصورت جداگانه با timestamp مشخص میکند و به مدل میگوید دقیقاً چه زمانی به شات بعدی برود. در راهنمای رسمی Kling 3.0 که از مدلهای پیشرو در این تکنیک است، تا ۶ شات متوالی در یک پرامپت پشتیبانی میشود.
این تکنیک بهصورت خاص برای روایتهای چندبخشی، پروموهای محصول، و ویدیوهای داستانی کاربرد دارد. مزیت بزرگ آن این است که شما بهجای ۴ بار اجرای پرامپت و دوختن ویدیوها به هم در پست، یک ویدیوی منسجم با continuity و پیوستگی طبیعی دریافت میکنید.
JSON Prompting؛ پیشرفتهترین تکنیک پرامپت ویدیو
اگر در توییتر یا فریپیک پرامپتهای موفق Veo3 را دیدهاید، احتمالاً متوجه شدهاید که خیلی از آنها به جای متن آزاد، از فرمت JSON استفاده میکنند. این یک ترند نیست. این یک تکنیک عمیقاً مؤثر است که در راهنماهای حرفهای، در حد یک «تغییر پارادایم» معرفی میشود. در یک بررسی فنی Architjn، آژانسهای استفادهکنندهی JSON prompting تا ۷۰ درصد کاهش در چرخههای اصلاح ویدیو گزارش کردهاند.
اما JSON prompting چیست؟ بهجای نوشتن یک پاراگراف توصیفی، شما هر عنصر ویدیو را در یک کلید-مقدار ساختاریافته تعریف میکنید. مثلاً بهجای «یک سگ گلدن رتریور با موهای روشن طلایی در حال نگاه کردن به کمد بسته در یک اتاق دنج»، مینویسید:
چرا JSON prompting مؤثرتر از پرامپت متنی است؟
سه دلیل اصلی برای برتری JSON prompting وجود دارد. اولین دلیل، شفافیت ساختاری است. وقتی هر عنصر در یک کلید جدا قرار میگیرد، مدل دقیقاً میداند آن کلمه کلیدی چه نقشی دارد. این برخلاف متن آزاد است که در آن «warm» میتواند به نور، رنگ، یا حالوهوا اشاره داشته باشد. در JSON، اگر «warm» در کلید lighting باشد، فقط روی نور اثر میگذارد. حالا بحث این که خود JSON چیست و کلید یا Key چه کارایی دارد می تواند در صورت درخواست شما موضوع مقاله بعدی ما باشد.
دومین دلیل، debugging آسان است. اگر ویدیوی نهایی نقصی دارد، مثلاً نور درست نیست، فقط آن کلید را تغییر میدهید، نه کل پرامپت را. این رویکرد شبیه نوشتن کد است که در آن هر تابع مسئولیت خاص خود را دارد. میتوانید چندین نسخه از پرامپت بسازید که فقط در کلید lighting یا camera متفاوتاند، تا A/B تست انجام دهید.
سومین دلیل، قابلیت بازتولید (templating) است. وقتی یک ساختار JSON موفق پیدا کردید، میتوانید آن را بهعنوان یک قالب نگه دارید و فقط مقادیر را برای پروژههای مختلف تغییر دهید. این کار، علاوه بر صرفهجویی در زمان، یک سطح از انسجام برند را در همهی ویدیوها تضمین میکند که با پرامپت دستی بهسختی قابل دستیابی است.
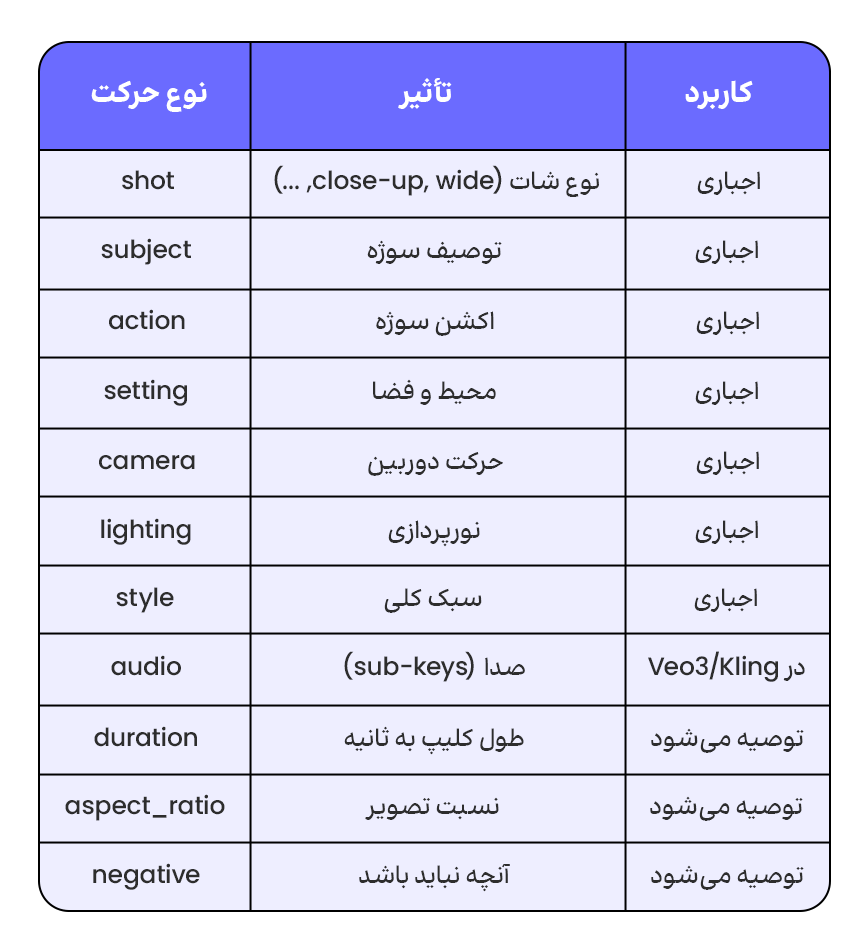
کلیدهای استاندارد در JSON prompting
هیچ استاندارد رسمی برای نام کلیدها وجود ندارد، اما در میان جامعهی حرفهای، یک سری کلید (key) همگرا شدهاند که در اکثر پرامپتهای موفق دیده میشوند:
نکتهی مهم:
JSON prompting در Veo3 و بعضی پلتفرمهای Seedance بومی پشتیبانی میشود. اما در Kling و بعضی نسخههای Runway، باید JSON را بهصورت متنی paste کنید. در این موارد، مدل ساختار را بهصورت context تشخیص میدهد، اما تأثیر آن کمی کمتر از مدلهای native است. در صورت شک، JSON بنویسید و امتحان کنید در اکثر موارد بهتر از متن آزاد عمل میکند.
مقایسهی Veo3، Seedance 2.0 و Kling 3.0 از زاویهی پرامپت
هر کدام از این سه مدل، نقاط قوت و ضعف متفاوتی دارند که در نحوهی نوشتن پرامپت اثر میگذارد. شناخت این تفاوتها، شما را از حالت «پرامپت یکسایز برای همه» نجات میدهد و کمک میکند برای هر مدل، ساختار بهینهی خودش را به کار ببرید.
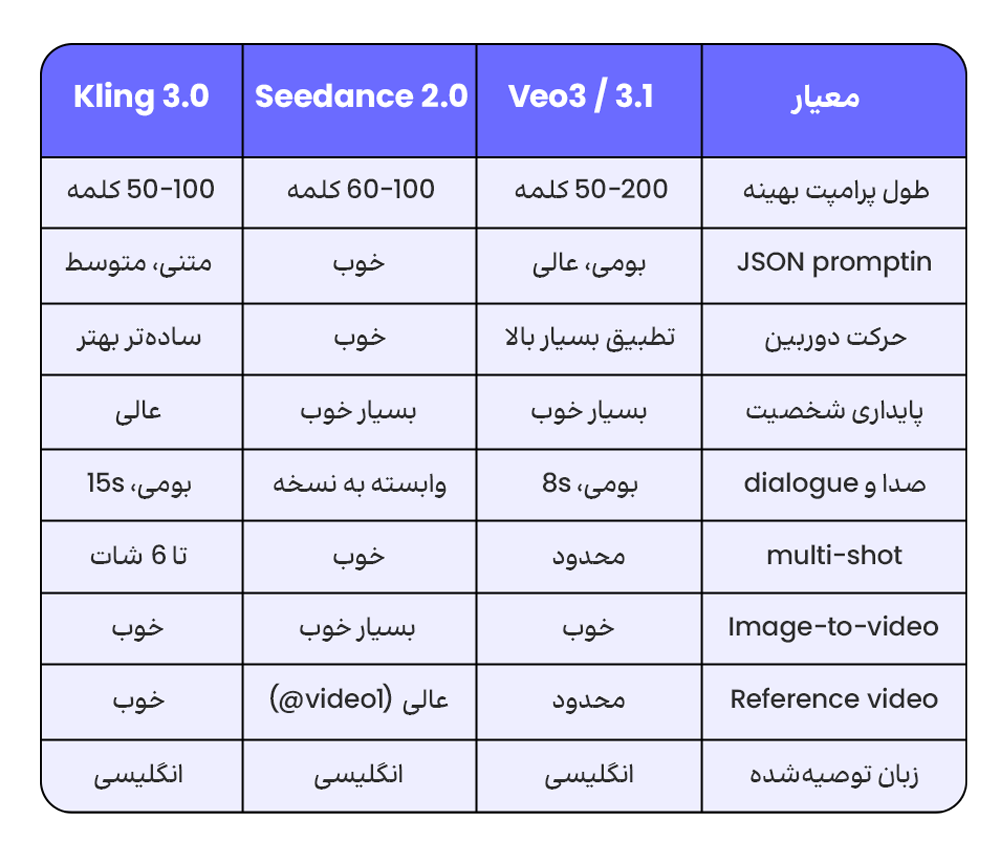
نقاط قوت هر مدل و چه زمانی استفاده کنیم
Veo3 برای محتوای سینمایی-روایتی نقطهی اوج است. واژگان فیلمسازی حرفهای را بهتر از همه تشخیص میدهد، JSON prompting را بهصورت بومی پشتیبانی میکند و در ترکیب صدا و تصویر بیرقیب است. اگر میخواهید یک شات سینمایی با dialogue واقعی، lip-sync دقیق، و فضای صوتی کامل بسازید، Veo3 انتخاب اول است. ضعف اصلیاش، طول کلیپ (حداکثر ۸ ثانیه) و دسترسی محدود است.
Seedance 2.0 برای کارهای multimodal و reference-based قدرت اول است. میتوانید یک تصویر برای شخصیت، یک ویدیو برای حرکت دوربین و یک کلیپ صوتی برای ریتم آپلود کنید و با @ منشن به آنها اشاره کنید. این رویکرد، که در بحث CRAFT framework مطرح است، برای پروژههای تجاری که نیاز به consistency بالا دارند فوقالعاده است. ضعف اصلیاش، وابستگی به کیفیت referenceهاست اگر reference ضعیف باشد، خروجی هم ضعیف میشود.
Kling 3.0 برای روایتهای چندشاتی و دیالوگ بلند بهترین انتخاب است. تنها مدلی است که در یک generation، تا ۱۵ ثانیه ویدیو با ۶ شات متوالی تولید میکند. این برای پروموهای محصول، short film و محتوای آگهی فوقالعاده است. اما برای یک شات سینمایی پیچیده با حرکت دوربین خاص، Veo3 برتری دارد. در راهنمای Kling 3.0 توصیه شده که instructionهای سادهٔ دوربین بهتر از واژگان پیچیدهی فیلمسازی کار میکنند برخلاف Veo3.
توصیهی عملی:
اگر تازه شروع کردهاید، با یک مدل شروع کنید و عمیقاً مسلط شوید، نه اینکه پراکنده با همه کار کنید. هر مدل یک «گرامر» متفاوت دارد و اگر ذهنتان بین چند گرامر جابهجا شود، در هیچکدام حرفهای نمیشوید. توصیهی شخصی ما برای طراحان: شروع با Seedance (یادگیری راحتتر، multimodal قوی)، بعد ارتقا به Veo3 (برای پروژههای سینمایی نهایی).
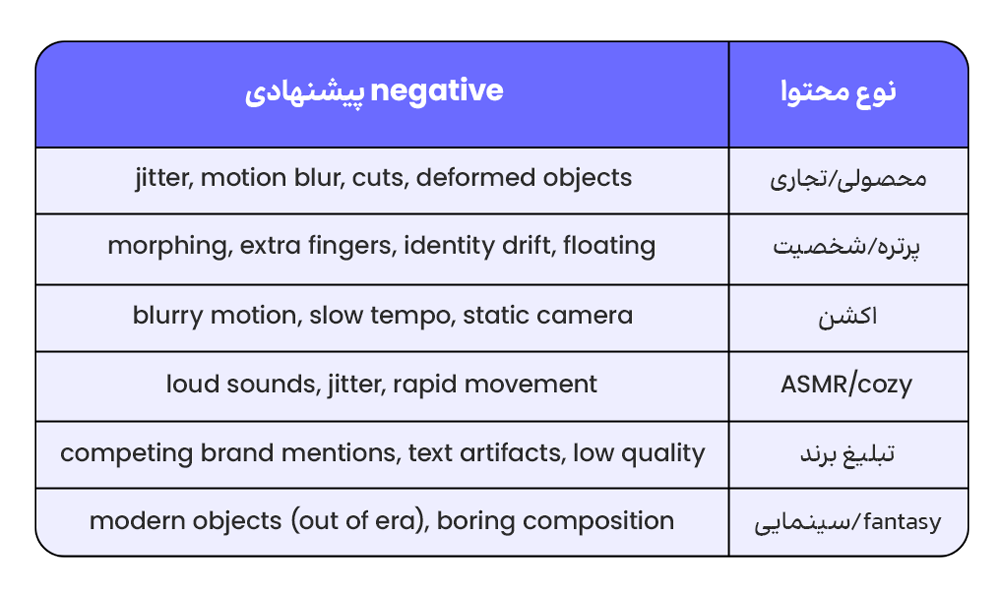
Negative Prompting؛ کنترل آنچه نباید باشد
یکی از قدرتمندترین تکنیکها در پرامپت ویدیو، گفتن صریح آنچه نباید در ویدیو باشد است. این تکنیک، در راهنمای رسمی Seedance 2.0 با عنوان «استاندارد طلایی» معرفی شده و در اکثر پرامپتهای حرفهای دیده میشود. بدون negative prompting، مدل تمایل دارد به سمت رفتارهای پیشفرضی برود که اغلب باعث افت کیفیت میشوند.
لیست استاندارد negative prompts برای ویدیو
بر اساس راهنماهای رسمی Veo3، Seedance، و Kling، یک لیست استاندارد از negative promptها وجود دارد که تقریباً در هر ویدیویی به کار میآید. میتوانید این لیست را بهعنوان یک قالب در همهی پرامپتهای خود استفاده کنید:
• jitter, shaky camera (مگر اینکه عمداً handheld بخواهید)
• morphing, shape-shifting, identity drift
• extra fingers, deformed hands
• floating feet, sliding feet
• text overlay, subtitles, captions, watermark
• flickering, strobing
• oversaturated colors, blown highlights
• cuts, scene transitions (در single-shot prompts)
• zoom (مگر اینکه صراحتاً بخواهید)
• static camera (در صحنههایی که حرکت میخواهید)
نکتهی مهم:
negative prompts باید متناسب با محتوای ویدیو انتخاب شوند، نه بهصورت کپی-پیست از یک لیست عمومی. مثلاً «no jitter» در یک ویدیوی action تیر و کمان، میتواند باعث شود ویدیو بیش از حد ساکن و بیجان شود. در عوض، در یک محتوای محصولی که میخواهید برند را نشان دهید، «no jitter» ضروری است. هنر اصلی، شناخت کانتکست هر ویدیوست.
Timeline Prompting؛ کنترل ثانیهبهثانیهی ویدیو
اگر JSON Prompting ساختار را به پرامپت میدهد، Timeline Prompting زمان را به آن اضافه میکند. این تکنیک پیشرفته، که در Seedance 2.0 و Kling 3.0 پشتیبانی میشود، به شما اجازه میدهد دقیقاً مشخص کنید در ثانیهی n چه اتفاقی باید بیفتد. بهجای یک توصیف کلی از ۱۰ ثانیه ویدیو، شما یک storyboard متنی میسازید که مدل آن را با دقت بالا پیاده میکند.
ایدهی اصلی این است: مدلهای ویدیویی بهصورت پیشفرض، یک «حرکت میانگین» در طول کل کلیپ میسازند. اما اگر شما بهطور صریح بگویید «در ثانیهی ۲ این اتفاق، در ثانیهی ۵ آن اتفاق»، مدل میتواند صحنهای با ریتم و توالی واقعی بسازد. این تکنیک بهخصوص برای روایتهای کوتاه، تبلیغات، و موزیک ویدیو فوقالعاده است.
ساختار استاندارد Timeline Prompt
سه قاعده برای Timeline Prompt موفق وجود دارد.
- اول، مدت هر بخش را کوتاه نگه دارید، معمولاً ۲ تا ۴ ثانیه. بخشهای طولانیتر باعث میشود مدل تصمیمات عمیقتری بگیرد که گاهی از کنترل شما خارج میشود.
- دوم، transition بین بخشها را مشخص کنید، آیا cut است؟ smooth transition است؟ camera follow است؟
- سوم، هر بخش باید یک «حرکت اصلی» داشته باشد، نه ۳ یا ۴ حرکت موازی.
نکتهی پیشرفته:
Timeline Prompting و JSON Prompting قابل ترکیباند. میتوانید یک JSON بسازید که در آن کلید «timeline» شامل آرایهای از shot objects باشد. این رویکرد بهخصوص برای ویدیوهای بلند (۳۰+ ثانیه) که در Kling قابل ساختاند، فوقالعاده مؤثر است.
تحلیل کامل یک پرامپت حرفهای؛ همهی تکنیکها در یک پرامپت
حالا که همهی تکنیکها را شناختیم، یک پرامپت کامل و پیشرفته را با هم تحلیل میکنیم. این پرامپت، یکی از پرامپتهای واقعی است که در Higgsfield و و روی مدل Seedance روی آن کار شده و خروجی شگفتانگیزی تولید میکند. ساختار آن از [STYLE] / [FORMAT] / [SCENE] / [CHARACTERS] / [CAMERA SYSTEM] استفاده میکند که یک bracket-style ترکیبی است.
چرا این پرامپت کار میکند؟ تحلیل قطعهبهقطعه
بخش [STYLE] یک تکنیک کلیدی به نام style stacking را به کار میبرد. بهجای یک کلمهی کلی مثل «cinematic»، چندین کلیدواژهی فنی را با هم ترکیب میکند: «Pixar-quality» (کیفیت رندر)، «8K» (رزولوشن)، «soft global illumination» (نوع نور)، «individual hair and fur strands» (جزئیات بافت)، «realistic fabric simulation» (فیزیک پارچه)، و «shallow depth of field» (عمق میدان). این چند لایه با هم، یک «امضای بصری» منسجم میسازند.
بخش [FORMAT] سه عنصر را تعیین میکند: نسبت تصویر، نوع شات، و ریتم. کلمهی «slow tension build» بسیار هوشمندانه است. این یک pacing instruction است که به مدل میگوید چطور انرژی را در طول ویدیو توزیع کند. بدون این جمله، مدل ممکن است انرژی صحنه را در همان ابتدا منفجر کند یا اصلاً نسازد.
بخش [SCENE] استانداردهای ستون «Environment» را به خوبی رعایت میکند: محیط فیزیکی (bedroom)، حالوهوا (cozy, 80s)، اشیاء خاص (retro posters, glowing computer)، و نور (warm lamp). نکتهی مهم اینکه «80s personality» یک کلیدواژهی هویتی است به مدل میگوید که نه فقط اشیاء بلکه «روح» این دوران را در صحنه پیاده کند: رنگهای گرم، تصاویر آنالوگ، حس نوستالژی.
بخش [CHARACTERS] نمونهی عالی از توصیف لمسی شخصیت است. بهجای «موهای فر»، «short dense curly blonde hair forming soft rounded clumps» نوشته شده توصیف بافت و فرم در یک سطح که مدل میتواند بهطور دقیق پیاده کند. مشابه آن «thick light golden fur» برای سگ نه فقط رنگ، بلکه ضخامت و طول مو هم تعریف شده. این نوع جزئیات، تفاوت بین یک ویدیوی «خوب» و یک ویدیوی «حرفهای» است.
بخش [CAMERA SYSTEM] یک ساختار سهوجهی دارد: نوع کلی حرکت (smooth cinematic)، انواع حرکتهای ترجیحی (slow push-ins, medium and close shots)، و یک negative explicit (no jitter). این ترکیب، به مدل اطمینان میدهد که حرکتها کنترلشده باشند و نه «نمایشگرانه». همچنین، عبارت «no jitter» بهصراحت مطرح شده که در همهی پرامپتهای شخصیتمحور استاندارد است.
بخش [ACTION] روایت را در ۵ جملهی متوالی توصیف میکند که هر جمله یک رویداد دارد. این یک Timeline Prompt پنهان است هرچند timestamp ندارد، ولی ترتیب رویدادها و تنوع آنها به مدل کمک میکند ریتم طبیعی صحنه را پیاده کند.
چطور این پرامپت را برای پروژهی خودتان تطبیق دهید
نکتهی کلیدی برای استفاده از این پرامپت بهعنوان قالب: بخشهای STYLE و CAMERA SYSTEM را ثابت نگه دارید، و بخشهای SCENE، CHARACTERS، و ACTION را با محتوای پروژهی خود جایگزین کنید. این رویکرد به شما اجازه میدهد یک «امضای بصری» منسجم بین چندین ویدیو حفظ کنید. اگر چند ویدیو برای یک کمپین تولید میکنید، با همین قالب و فقط تغییر در ACTION، انسجام بصری بین آنها تضمین میشود.
یک تجربهی واقعی:
یکی از کاربران فریپیک این پرامپت را در Seedance و سپس Higgsfield امتحان کرده و گزارش داده که خروجی هر دو مدل، کیفیتی نزدیک به انیمیشن استودیویی داشته. علت اصلی، استفاده از کلیدواژههای فنی فیلمسازی است که در دادههای آموزشی این مدلها بهخوبی نمایندگی شدهاند. این یعنی هرچه واژگان شما حرفهایتر باشد، خروجی هم به سطح حرفهای نزدیکتر است.
هفت اشتباه رایج در هوش مصنوعی ویدیو که نباید مرتکب شوید
شناختن اشتباهات رایج، گاهی مهمتر از شناختن تکنیکهای موفق است. در این بخش، هفت الگوی پرتکرار را بررسی میکنیم که حتی کاربران باتجربه هم گاهی در دام آنها میافتند.
اشتباه ۱: ترکیب چند حرکت دوربین در یک پرامپت
نوشتن «دوربین میچرخد، زوم میکند و سوژه را تعقیب میکند» تقریباً همیشه باعث جیتر میشود. هر کلیپ یک حرکت اصلی دوربین را خوب اجرا میکند، نه بیشتر. اگر چند حرکت میخواهید، از Timeline Prompting یا multi-shot استفاده کنید.
اشتباه ۲: استفاده از کلمهی «fast»
کلمهی «fast» در پرامپت ویدیو، خطرناکترین کلمه است. در ترکیب با عناصر دیگر، اغلب باعث افت کیفیت میشود. بهجای آن، از «smooth», «quick but stable», یا «accelerated yet smooth» استفاده کنید. اگر نیاز به سرعت بالا دارید، فقط یک عنصر را سریع کنید، نه همه را.
اشتباه ۳: مخلوط کردن حرکت دوربین و حرکت سوژه
«دوربین میچرخد دور یک رقصندهی در حال رقصیدن» باعث میشود مدل گیج شود. بهجای آن، در دو جمله جدا بنویسید: «رقصنده آرام میچرخد. دوربین قاب ثابت دارد». این جداسازی، یکی از پایهایترین قواعد است.
اشتباه ۴: ترجمهی مستقیم پرامپت تصویر به ویدیو
پرامپتی که برای Midjourney خوب کار میکند، اغلب در Veo3 ضعیف عمل میکند. تصویر یک «لحظه» را میسازد، ویدیو یک «بازه» را. عناصر زمانی، حرکت دوربین، و فیزیک باید جداگانه و صریح اضافه شوند.
اشتباه ۵: نادیده گرفتن طول کلیپ
سعی در فشردن یک روایت ۳۰ ثانیهای در یک کلیپ ۸ ثانیهای، نتیجهی نامطلوب میدهد. مدل گیج میشود و یا اکشن را فشرده میکند یا بخشی از روایت را حذف میکند. هر کلیپ ویدیویی، یک اکشن اصلی را خوب اجرا میکند.
اشتباه ۶: استفاده از زبان فارسی برای پرامپت
اکثر مدلهای ویدیویی، روی دادههای انگلیسی آموزش دیدهاند. حتی اگر فارسی را تشخیص دهند، عملکرد آنها روی واژگان فنی فیلمسازی به فارسی بهمراتب ضعیفتر است. توصیهی قوی: پرامپتها را به انگلیسی بنویسید، حتی اگر context پروژه فارسی است.
اشتباه ۷: کپی پرامپتهای آماده بدون تطبیق
پرامپتهایی که در پلتفرمهای اشتراکگذاری پیدا میکنید، اغلب برای مدل خاصی بهینه شدهاند. کپی مستقیم آنها در یک مدل دیگر، گاهی نتیجهی ضعیف میدهد. هر مدل گرامر خاص خود را دارد و پرامپت موفق در Veo3 ممکن است در Kling خوب کار نکند.
سؤالات متداول دربارهی پرامپتنویسی ویدیویی
کدام مدل برای شروع برای یک طراح ایرانی توصیه میشود؟
اگر تازه شروع میکنید و دسترسی محدود دارید، Kling 3.0 معمولاً انتخاب اول است چون در پلتفرمهای third-party در دسترستر است و گرامر سادهتری دارد. اگر دسترسی به Veo3 دارید، آن انتخاب اول برای پروژههای سینمایی است. Seedance 2.0 برای کاربرانی که نیاز به reference-based generation دارند (مثل تطبیق با یک تصویر برند موجود)، فوقالعاده است. اما توصیهی کلی این است که با یک مدل شروع کنید و عمیقاً مسلط شوید، نه اینکه پراکنده با همه کار کنید.
آیا واقعاً JSON prompt بهتر از پرامپت متنی است؟
در Veo3، بله. JSON prompting در این مدل بهصورت بومی پشتیبانی میشود و در آژانسهای حرفهای، استاندارد شده است. در Seedance، عملکرد JSON خوب اما نه فوقالعاده است. در Kling 3.0 و Runway، JSON تأثیر کمتری دارد و گاهی پرامپت متنی روان عملکرد بهتری دارد. در صورت شک، JSON را امتحان کنید و خروجی را با نسخهی متنی مقایسه کنید. این یکی از سریعترین A/B testهایی است که میتوانید انجام دهید.
طول بهینهی یک پرامپت ویدیویی چقدر است؟
در پرامپت متنی، ۵۰ تا ۱۵۰ کلمه برای اکثر مدلها بهینه است. پرامپتهای زیر ۳۰ کلمه اغلب ابهام زیاد دارند و پرامپتهای بالای ۲۰۰ کلمه ممکن است باعث شوند مدل عناصر مهم را گم کند. در JSON Prompting، اندازه کمتر مهم است. میتوانید ۲۰ کلید بسازید، چون ساختار به مدل کمک میکند هر کدام را بهدرستی پردازش کند. اما باز هم، هر کلید باید اطلاعات معنادار داشته باشد، نه پرکننده.
چرا ویدیوی من جیتر دارد؟
شایعترین علل جیتر این موارد هستند: ترکیب چند حرکت دوربین، استفاده از کلمهی «fast»، صحنهی شلوغ با پسزمینهی پرجزئیات، و مخلوط کردن حرکت دوربین با حرکت سوژه. اولین کار: «no jitter» را بهصراحت در negative prompt اضافه کنید. اگر کافی نبود، پرامپت را ساده کنید. یک حرکت دوربین، یک سوژهی اصلی، پسزمینهی کمجزئیات. اغلب با همین تغییرات ساده، جیتر برطرف میشود.
چطور شخصیت ثابتی بین چند ویدیو حفظ کنم؟
سه روش وجود دارد. اول، از reference image یا reference video استفاده کنید (در Seedance با @ mention). دوم، توصیف شخصیت را بهصورت یک قالب متنی ثابت نگه دارید و در همهی پرامپتهای آن شخصیت تکرار کنید. سوم، در مدلهایی که از character consistency بومی پشتیبانی میکنند (مثل Kling 3.0)، از feature آن استفاده کنید. هیچ روشی ۱۰۰٪ بینقص نیست، ولی ترکیب این سه روش معمولاً ۸۰-۹۰٪ پایداری میدهد که برای اکثر کاربردها کافی است.
Negative prompt چقدر مهم است؟
بسیار مهم. در یک تست داخلی روی ۱۰۰ پرامپت Seedance، اضافه کردن یک لیست استاندارد negative prompt کیفیت خروجی را بهطور میانگین ۲۵ تا ۳۵ درصد بهبود داده است. بدون negative prompt، مدل به سمت رفتارهای پیشفرض میرود که اغلب نامطلوب هستند: جیتر، morphing، floating feet. حتی یک لیست ساده (jitter, morphing, floating, text overlay) تأثیر بزرگی دارد.
جمعبندی: کارگردانی بهجای نوشتن
اگر یک پیام کلیدی از این مقاله باید با خود ببرید، این است: پرامپتنویسی برای ویدیو AI، شکل دیگری از کارگردانی است. شما دیگر یک نویسنده نیستید. یک کارگردان هستید که با کلمات، یک صحنهی واقعی را به استدیوی ذهن مدل دیکته میکنید. هرچه دیکشنری شما دقیقتر، ساختار شما منظمتر و کنترل شما هدفمندتر، خروجی هم به سطح حرفهای نزدیکتر است.
این مقاله یک نقشهی راه به شما داد: از سه تفاوت بنیادی پرامپت ویدیو با LLM، تا ساختار ششبخشی، تا حرکت دوربین، JSON Prompting، Timeline Prompting، negative prompts، و در نهایت تحلیل یک پرامپت کامل. هیچکدام از این تکنیکها بهتنهایی شما را به یک کاربر حرفهای تبدیل نمیکند، اما ترکیب آنها در یک workflow منسجم، تفاوت چشمگیری ایجاد میکند.
توصیهی نهایی: همین امروز، یک پرامپت سادهی موجود خود را بردارید و سعی کنید آن را با یک ساختار ششبخشی بازنویسی کنید. سپس همان مفهوم را به فرمت JSON دربیاورید. تفاوت خروجی را با چشم خود ببینید. تجربهی مستقیم، بهترین معلم پرامپتنویسی ویدیویی است.



















با عرض سلام و درود، خداقوت به شما اقای اعتمادی
بسیار جامع،عالی و کاربردی و کار راه انداز بود ، سپاسگزارم
ممنونم از وقتی که گذاشتید.