


Qwen 3.6 منتشر شد؛ غول کدنویسی چینی حالا قویتر از همیشه
اگر طراحی هستی که توی یکی دو سال گذشته با ابزارهای هوش مصنوعی کار کردهای، احتمالاً اسم Qwen به گوشت خورده. مدلهای چینیای که با سرعت عجیبی دارن پیش میآن و حالا با نسخهی ۳.۶، رسماً وارد میدان رقابت با Claude و GPT شدهاند.
چرا این موضوع برای یه طراح یا موشندیزاینر مهمه؟ چون Qwen 3.6 در حوزههایی قوی شده که مستقیماً به کار روزمرهی ما میآد: تولید کد frontend از طرح، نوشتن پرامپت برای ابزارهای هنر دیجیتال، درک بهتر از تصاویر و اسناد، و مهمتر از همه، یه نسخهی متنباز که میشه لوکال اجراش کرد.
توی این مقاله با هم نگاهی میاندازیم به اینکه Qwen 3.6 دقیقاً چیه، توی بنچمارکها چطور ظاهر شده، و مهمتر از همه، چطور میتونی ازش توی پروسهی طراحی خودت استفاده کنی.
باکس دانلود 12 اردیبهشت بروز شد (قرار گیری وزن های جدید)
Qwen 3.6 چیست و چه تغییری نسبت به نسخهی قبلی داشته؟
Qwen خانوادهای از مدلهای زبانی بزرگ است که توسط علیبابا (Alibaba) توسعه داده میشه. نسخهی ۳.۶ در واقع یک مدل واحد نیست، بلکه مجموعهای از چند مدل با اندازهها و کاربردهای متفاوت است.
سه عضو اصلی خانوادهی Qwen 3.6
Qwen 3.6 Max (Preview): پرچمدار خانواده و تازهترین عضو. طبق اعلام رسمی حساب @Alibaba_Qwen در ۲۰ آوریل ۲۰۲۶، این مدل «پیشنمایش اولیهای از مدل پرچمدار بعدی ما» توصیف شده. سه ویژگی کلیدیاش: قابلیت کدنویسی agentic بهتر از Qwen3.6-Plus، دانش جهانی و instruction following قویتر، و عملکرد قابل اعتمادتر در کارهای agent در دنیای واقعی.
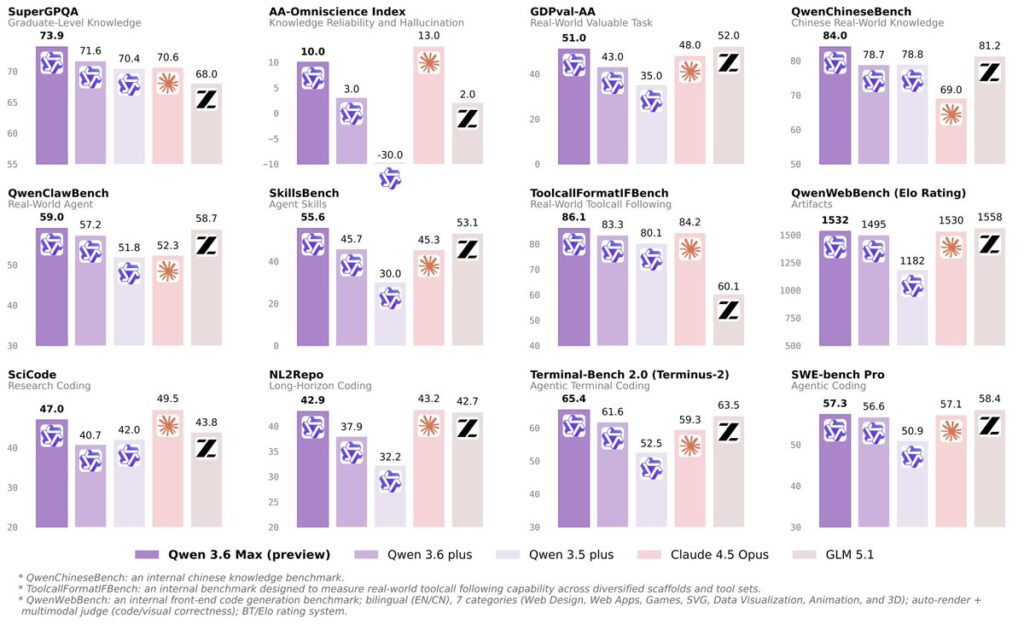
Qwen 3.6 Plus: نسخهی عمومیتر که هفتهها قبل از Max منتشر شد و همین الان روی پلتفرمهای مختلف در دسترسه. در Code Arena (رتبهبندی توسعهی agentic وب) با امتیاز ۱۴۷۶ در رتبهی ۷ قرار گرفته — جایگاهی که فقط مدلهای Claude و GLM ازش بالاتر هستن.
Qwen 3.6-35B-A3B: نسخهی کوچکتر با معماری MoE (Mixture of Experts). از ۳۵ میلیارد پارامتر کل، فقط حدود ۳ میلیارد پارامتر در هر بار استفاده فعاله. این مدل برای اجرای لوکال و سرورهای کوچکتر طراحی شده و همونطور که در بخش بنچمارکها میبینیم، توی خیلی از حوزهها از مدلهای خیلی بزرگتر جلو زده.
نسبت به Qwen 3.5، جهش اصلی توی سه حوزه است: کدنویسی agentic (قابلیت انجام کارهای چندمرحلهای مثل رفع باگ در یه ریپازیتوری)، درک بهتر از ابزارها و APIها (tool calling)، و کاهش محسوس hallucination یا توهمزایی. اینها همه بهطور مستقیم در نمودارهای بنچمارک رسمی Qwen قابل مشاهدهاند.
بنچمارکها: Qwen 3.6 کجا ایستاده؟
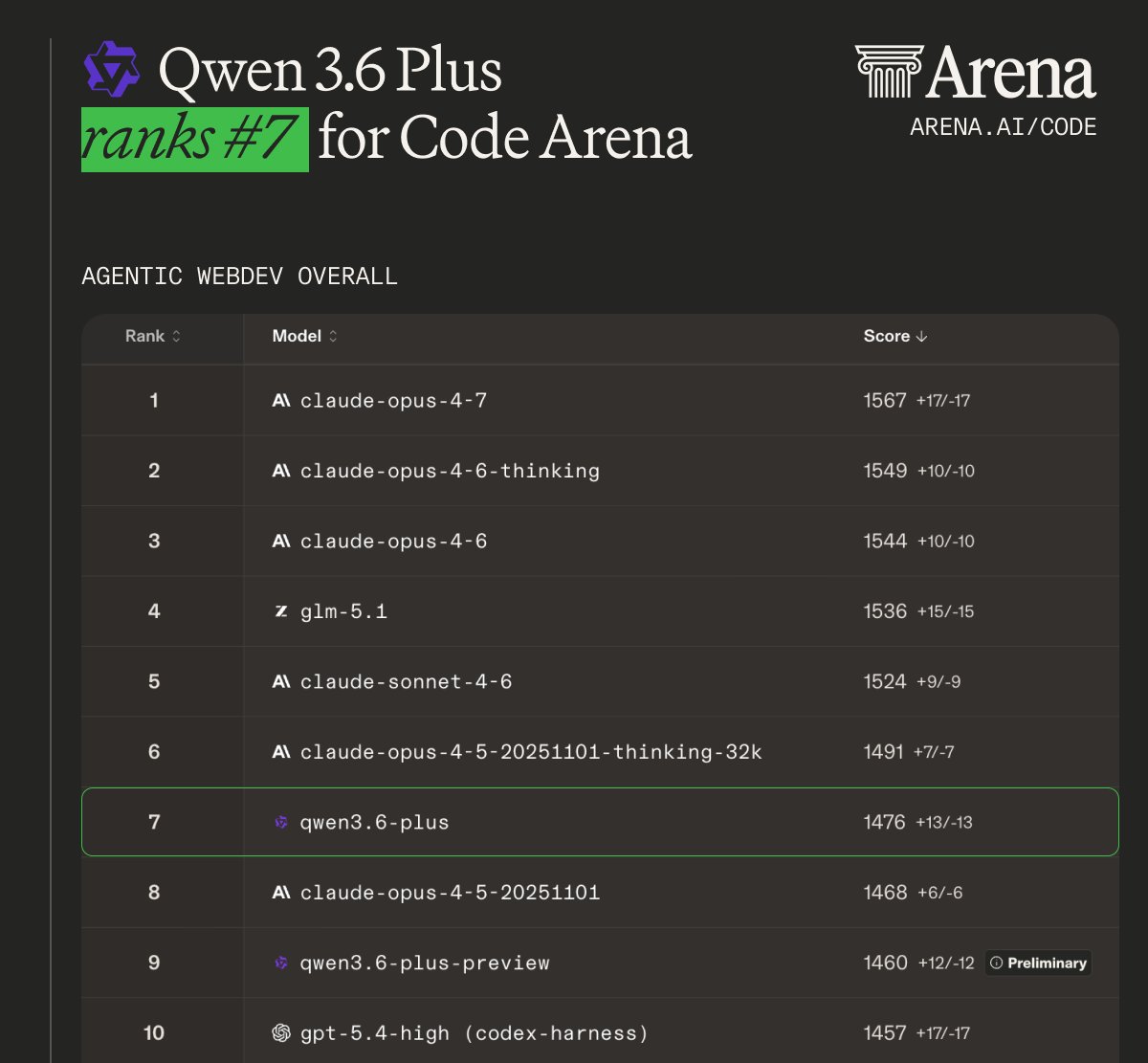
قبل از نگاه به اعداد، یه تذکر مهم: بعضی از این بنچمارکها مثل QwenChineseBench، QwenClawBench و QwenWebBench توسط خود تیم Qwen طراحی شدن. این یعنی باید با کمی احتیاط نگاهشون کرد، ولی بنچمارکهای عمومیتر مثل SuperGPQA، SWE-bench و AIME هم توی منابع هستن و تصویر نسبتاً کاملی میدن.
Qwen 3.6 Max در برابر رقبا
طبق نمودار رسمی منتشرشده توسط Alibaba_Qwen، در بنچمارکهای کلیدی، Qwen 3.6 Max این اعداد رو گرفته است. نگاه تحلیلی: Qwen 3.6 Max توی دانش عمومی (SuperGPQA) و مهارت agent بیرقیبه، ولی توی کدنویسی خالص agentic مثل SWE-bench Pro هنوز کمی پشت GLM 5.1 قرار داره. یه نکتهی جالب: در شاخص AA-Omniscience (که hallucination رو اندازه میگیره)، Qwen 3.6 Max امتیاز ۱۰.۰ گرفته در حالی که Qwen 3.5 Plus امتیاز منفی ۳۰.۰ داشته. یعنی بهطور قابل توجهی کمتر «توهم» میزنه.
نگاه تحلیلی: Qwen 3.6 Max توی دانش عمومی (SuperGPQA) و مهارت agent بیرقیبه، ولی توی کدنویسی خالص agentic مثل SWE-bench Pro هنوز کمی پشت GLM 5.1 قرار داره. یه نکتهی جالب: در شاخص AA-Omniscience (که hallucination رو اندازه میگیره)، Qwen 3.6 Max امتیاز ۱۰.۰ گرفته در حالی که Qwen 3.5 Plus امتیاز منفی ۳۰.۰ داشته — یعنی بهطور قابل توجهی کمتر «توهم» میزنه.
Plus در Code Arena
طبق گزارش رسمی Arena.ai، نسخهی Plus توی رتبهبندی Code Arena با امتیاز ۱۴۷۶ در جایگاه هفتم ایستاده و علیبابا رو به رتبهی سوم آزمایشگاههای کدنویسی رسونده. رتبههای بالاتر از Qwen عمدتاً در دست مدلهای Claude (از Opus 4.7 تا Sonnet 4.6) و GLM 5.1 هستن. نکتهی جالب اینکه Qwen 3.6 Plus از GPT-5.4-high هم بالاتر قرار گرفته.
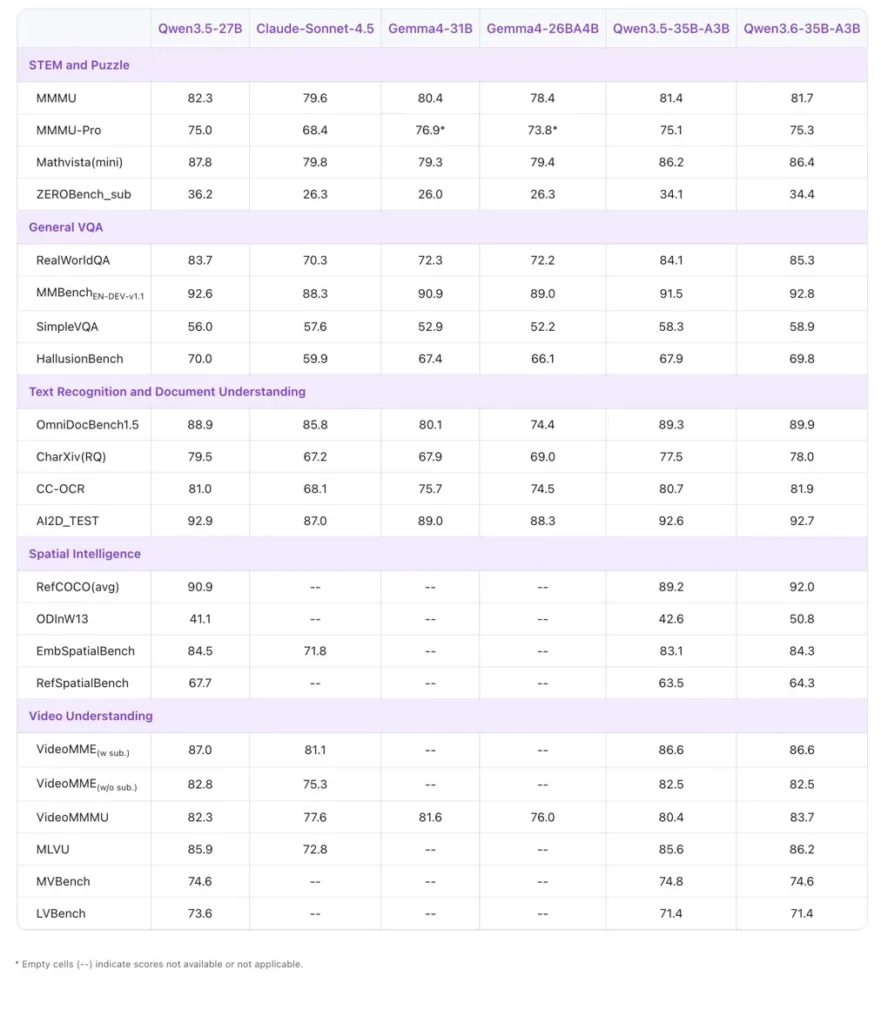
مدل کوچک Qwen 3.6-35B-A3B چطور؟
این قسمت واقعاً جالبه. نسخهی کوچک MoE (که فقط ۳ میلیارد پارامتر در هر بار فعاله) در خیلی از بنچمارکها از Gemma4-31B و حتی از Qwen3.5-27B قبلی جلو زده:
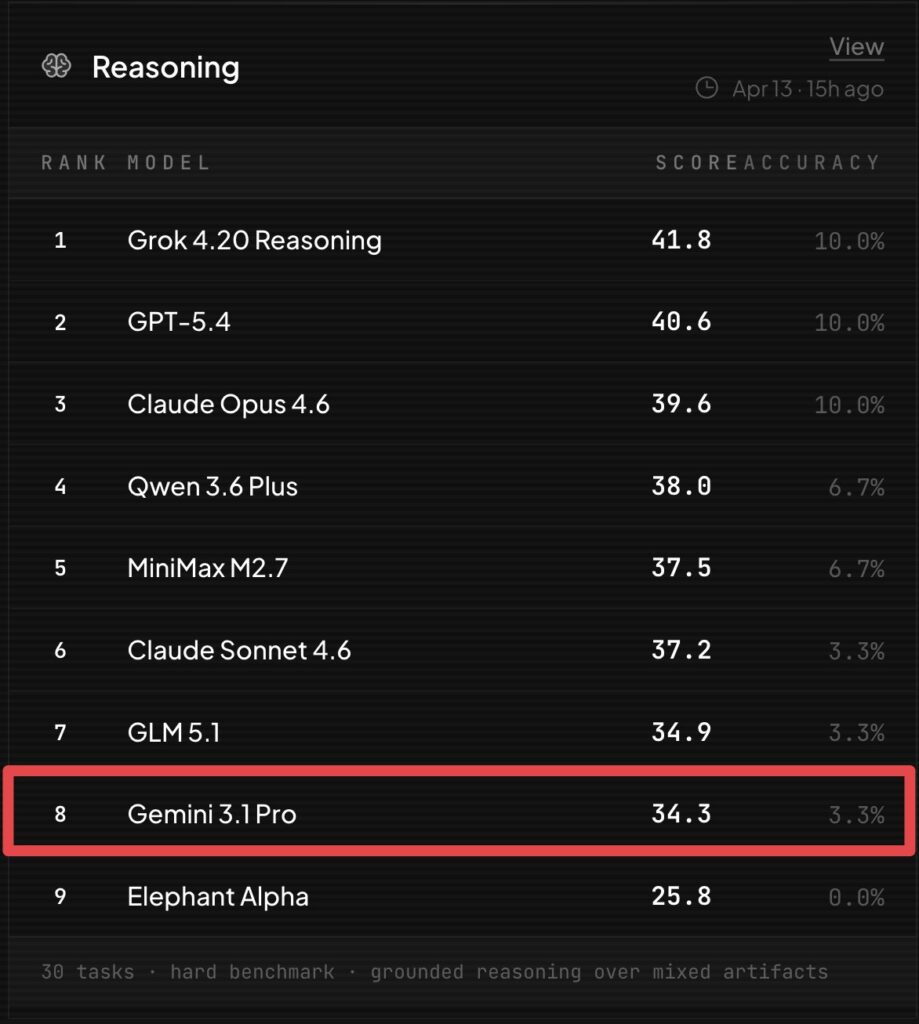
یه نکتهی بامزه: در جدول Bridgebench که توییت @bridgebench اون رو منتشر کرده، در بنچمارک Reasoning، Qwen 3.6 Plus با امتیاز ۳۸.۰ در رتبهی چهارم قرار گرفته، بالاتر از Claude Sonnet 4.6، GLM 5.1، و جالبتر از همه، Gemini 3.1 Pro از گوگل. به گفتهی @bridgebench، «مدل پرچمدار گوگل حتی نمیتونه روی یه مدل چینی رایگان در استدلال grounded برتر باشه».
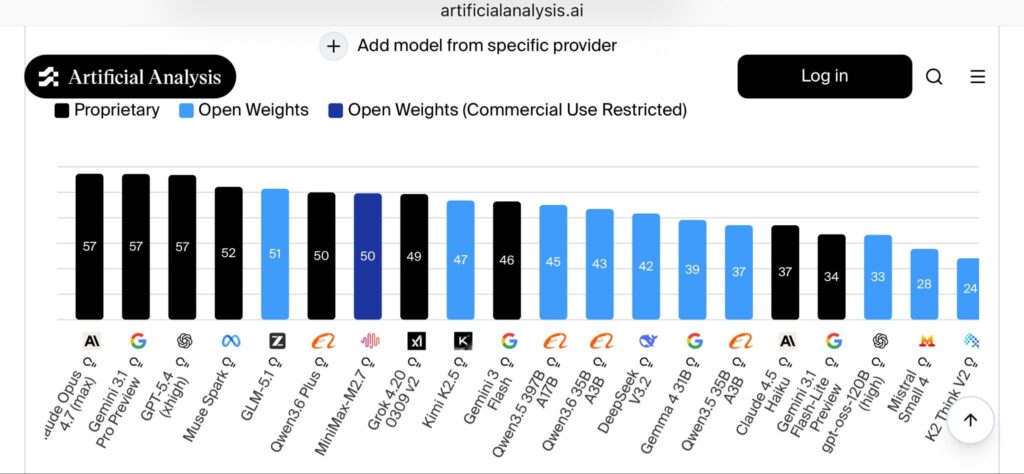
در ردهبندی کلی Artificial Analysis، Qwen 3.6 Plus با امتیاز ۵۰ رتبهی ششم رو داره — پشت Claude Opus 4.7 (۵۷)، Gemini 3.1 Pro Preview (۵۷)، GPT-5.4 (۵۷)، Muse Spark (۵۲) و GLM-5.1 (۵۱). این یعنی یکی از بهترین مدلهای متنباز (open weights) موجوده.
Qwen 3.6 برای طراحها چه کاری میتونه بکنه؟
اعداد بنچمارک جذابن، ولی سؤال اصلی اینه: من بهعنوان طراح یا موشندیزاینر چطور میتونم ازش استفاده کنم؟ چند سناریوی واقعی:
۱. ساختن کد frontend از طرح فیگما
یکی از نقاط قوت واقعی Qwen 3.6 همین بخشه. طبق QwenWebBench (که مخصوص کدنویسی frontend و هفت دسته مثل Web Design، Web Apps، SVG و Data Visualization طراحی شده)، نسخهی Max امتیاز Elo برابر ۱۵۳۲ گرفته. یعنی اگه داری یه لندینگ پیج یا کامپوننت Next.js میسازی، Qwen میتونه کمک جدی کنه. چه مستقیم، چه از طریق Claude Code یا ابزارهای مشابه.
۲. نوشتن پرامپت برای ابزارهای هنر دیجیتال
چون Qwen درک زبانی قوی داره (MMLU-Redux = ۹۳.۳)، میتونی ازش بخوای پرامپتهای دقیقتر برای Midjourney، Stable Diffusion یا ComfyUI بنویسه. مخصوصاً وقتی با یه ایدهی مبهم شروع میکنی و نیاز داری اون رو به زبان بصری و سینمایی ترجمه کنی.
۳. ترجمه و بومیسازی محتوا
اگرچه تست رسمی فارسی در منابع نیست، ولی Qwen بهخاطر تمرکز علیبابا روی بازارهای غیرانگلیسی، در زبانهای چندگانه قوی عمل میکنه (SWE-bench Multilingual = ۶۷.۲). برای ترجمهی مقالات آموزشی یا بومیسازی محتوای خارجی، گزینهی قابل اعتمادیه.
۴. خودکارسازی کارهای تکراری طراحی
قابلیت tool calling بهبود یافته یعنی میتونی Qwen رو به اسکریپتهای Photoshop، After Effects یا Figma وصل کنی و کارهای تکراری رو بهش بسپری. ToolcallFormatIFBench نشون میده Qwen 3.6 Max (با ۸۶.۱) بهتر از بقیه این فرمتها رو رعایت میکنه.
۵. درک تصویر و اسناد
نسخهی مولتیمدال Qwen 3.6-35B-A3B توی OmniDocBench1.5 امتیاز ۸۹.۹ گرفته که از Claude Sonnet 4.5 (با ۸۵.۸) بالاتره. اگه با اسناد PDF، اسکرینشاتهای طرح، یا چارتهای داده سروکار داری، این نقطهی قوت مهمیه.
نقد ضمنی: «Preview» یعنی چی؟
خود تیم Qwen در اعلام رسمی تأکید کرده که نسخهی Max یه «پیشنمایش» (Preview) است و «هوشمندتر، تیزتر، هنوز در حال تکامل». این یعنی احتمال تغییر رفتار یا حتی retire شدن این نسخه در آینده وجود داره. برای پروژههای پروداکشن جدی، شاید بهتر باشه روی Qwen 3.6 Plus که پایدارتره تکیه کنی.
عقبنشینی جالب از Gemini
حساب @bridgebench در تحلیل بنچمارک استدلال خودش نوشته: «Gemini 3.1 Pro در بین مدلهای پیشرفته در BridgeBench Reasoning آخر شد. پشت Grok 4.20، GPT 5.4، Claude Opus 4.6، Qwen 3.6 Plus، MiniMax M2.7، Claude Sonnet 4.6 و GLM 5.1.» این نشون میده Qwen دیگه فقط یه مدل «ارزانقیمت چینی» نیست.
چطور به Qwen 3.6 دسترسی داشته باشیم؟
طبق اعلام رسمی، سه روش اصلی برای دسترسی به Qwen 3.6 Max وجود داره:
Qwen Studio: از طریق chat.qwen.ai میتونی مستقیم با مدل چت کنی. رابط کاربری تمیز و مشابه ChatGPT داره.
API: از طریق پلتفرم Alibaba Cloud Model Studio (modelstudio.console.alibabacloud.com) میتونی API بگیری. این مناسب توسعهدهندههاییه که میخوان مدل رو در اپلیکیشن خودشون استفاده کنن.
بلاگ رسمی: اطلاعات تفصیلیتر در qwen.ai/blog موجوده.
برای نسخهی متنباز Qwen 3.6-35B-A3B، معمولاً Hugging Face و ModelScope مراجع اصلی هستن، لینک تیم unsloth
نکته برای کاربران ایرانی
صادقانه بگم: دسترسی مستقیم به chat.qwen.ai و API علیبابا کلاود از ایران معمولاً مشکلساز میشه. برای استفادهی پایدار، یا به VPN نیاز داری، یا باید از واسطههای چینی/ترکی استفاده کنی. گزینهی عملیتر برای کاربر ایرانی، دانلود نسخهی متنباز Qwen 3.6-35B-A3B از Hugging Face و اجرای لوکال با ابزارهایی مثل Ollama یا LM Studio است. در انتهای این مقاله به مرور لینک ها رو تکمیل میکنیم.
جمعبندی: Qwen 3.6 برای کی مناسبه؟
Qwen 3.6 یه خانوادهی جدیه که خصوصاً برای طراحهایی که به کدنویسی frontend، تولید SVG، یا کار با ابزارهای agent علاقه دارن، ارزش تست کردن داره. نسخهی Plus الان پایدارترین گزینه است، Max برای کسانیه که میخوان آخرین قابلیتها رو تست کنن، و 35B-A3B انتخابیه برای اجرای لوکال و محیطهای محدود.
ولی اگه کارت سنگینترین پروژههای پروداکشنه و نیاز به پایداری بلندمدت داری، Claude Opus که اخیرا ورژن 4.7 اون سرو صدای زیادی کرده یا GPT-5 هنوز کمی جلوترن.هم از نظر اکوسیستم ابزارها و هم از نظر قابلیتهای ظریفتر.
تو از Qwen استفاده کردی؟ تجربهت چطور بوده؟ توی کامنتها یا کانال تلگرام بگو تا گفتگو رو ادامه بدیم.
سوالات متداول دربارهی Qwen 3.6
- Qwen 3.6 چیست؟
Qwen 3.6 جدیدترین خانوادهی مدلهای زبانی بزرگ علیبابا است که شامل سه نسخهی اصلی میشود: Max (پرچمدار و در حال پیشنمایش)، Plus (نسخهی پایدار عمومی)، و 35B-A3B (نسخهی کوچک و متنباز با معماری MoE). این خانواده در کدنویسی، استدلال و درک مولتیمدال جهش قابل توجهی داشته.
- آیا Qwen 3.6 از Claude و GPT بهتر است؟
در بعضی حوزهها بله، در بعضی نه. در بنچمارکهای استدلال (مثل BridgeBench) و ساخت آرتیفکتهای وب، Qwen 3.6 Plus از Gemini 3.1 Pro جلو زده و با Claude Sonnet 4.6 رقابت میکنه. ولی Claude Opus 4.7 همچنان در ردهبندی کلی Artificial Analysis برتر است.
- آیا میتوانم Qwen 3.6 را بهصورت رایگان استفاده کنم؟
بله، نسخهی 35B-A3B بهصورت متنباز قابل دانلود است و میتونی روی کامپیوتر خودت اجراش کنی (البته سختافزار قوی لازمه). نسخههای Plus و Max از طریق Qwen Studio قابل استفادهاند، اگرچه API معمولاً بر اساس مصرف هزینه داره.
- Qwen 3.6 برای کدنویسی frontend چطور است؟
خیلی خوب. در بنچمارک QwenWebBench که مخصوص کدنویسی frontend و SVG طراحی شده، نسخهی Max امتیاز Elo برابر ۱۵۳۲ گرفته. در Code Arena هم نسخهی Plus در رتبهی ۷ قرار داره، بالاتر از GPT-5.4. برای ساخت کامپوننتهای React، HTML/CSS و انیمیشن SVG گزینهی جدیایه.
- آیا Qwen 3.6 از فارسی پشتیبانی میکند؟
در منابع رسمی بنچمارک اختصاصی برای فارسی منتشر نشده، ولی Qwen در زبانهای چندگانه عملکرد خوبی داره (SWE-bench Multilingual = ۶۷.۲). تجربهی کاربران نشون داده کیفیت فارسیاش قابل قبول است، اگرچه هنوز به سطح Claude و GPT نرسیده.
راهنمای دانلود:
اگر به عنوان مثال سیستم شما 12 گیگابایت VRAM و 32 گیگابایت RAM دارد. اگر شما مدل 22 گیگابایتی را دانلود کنید. حدود 12 گیگ آن در گرافیک شما و الباقی یعنی 10 گیگ آن توسط RAM شما اجرا خواهد شد. پس به مجموع VRAM + RAM دقت کنید.
لینک دانلود نرم افزار LM Studio – نسخه win-mac-linux
قرارگیری مدل ها با کمک آقای حمیدیان انجام شده است؛ برای تداوم این روند و حفظ دسترسی پایدار، در صورت تمایل میتوانید از ایشان حمایت مالی کنید. همچنین میتوانید موقع حمایت، مدل مدنظرتان را در توضیحات بنویسید.



















سلام وقتتون بخیر
امکانش هست این مدل هارو از Qwen قرار بدید؟ خیلی لازم دارم
Qwen3-ASR-0.6B
Qwen3-ASR-Flash
Qwen3-ASR-1.7B
متشکرم ازتون
درود دوستان درخواست هاتون لطفا با لینک به صفحه ریپو باشه. متاسفانه فرصت نمیشه دیگه سرچ کرد.
سلام
واقعا ممنون بابت مطلب مفیدتون
جدا از درنظر گرفتن حجم بین مدل های A3B که قرار دادین HauhauCS و UD کدام را پیشنهاد میکنید؟
تشکر
بین دو کوانت HauHauCS و UD، گزینه UD (Unsloth Dynamic) در اکثر سناریوها ارجحیت دارد؛ چون Unsloth با کوانتیزاسیون داینامیک لایهبهلایه کار میکند. یعنی لایههای حساستر مدل (مثل attention و embedding) با دقت بالاتر (Q6/Q8) نگه داشته میشوند و لایههای کماهمیتتر با دقت پایینتر، که نتیجهاش کیفیت خروجی بهتر نسبت به حجم فایل است. در مقابل، HauHauCS (از IQ/فرمتهای importance-quantized سری Charlie) هم رویکرد هوشمندانهای دارد و گاهی در benchmarkهای perplexity رقابتیتر است، اما برای مدلهای MoE مثل Qwen3-A3B که اکسپرتهای sparse دارند، UD معمولاً پایداری بیشتری در توکنزنی فارسی و زبانهای چندگانه نشان میدهد. بهخصوص اگر از llama.cpp یا LM Studio استفاده میکنید که پشتیبانی بهتری از فرمت Unsloth دارند.
سلام
واقعا دستتون درد نکنه. خیلی زحمت میکشید
لطفاً یه مدل سبک برای سیستم هایی که ضعیف هستن هم قرار بدید برای (برنامه نویسی)
من کلاً 16 رم بیشتر ندارم و گرافیکم هم اجرا نمیشه
بازهم تشکر🌹
سلام خسته نباشید
بنده این مدل qwen3.6 q4-k-m رو دانلود کردم و توی lm studio وقتی مخیام ازش استفاده کنم امکان بارگذاری تصویر رو نداره
در صورتی که مدلهایی که قبلا مستقیما توسط خود lm studio دانلود کردم این مشکل رو ندارن
شما علتش رو میدونید؟
باید مدل ویژن رو هم دانلود کنید.
سلام اگه میشه لطف کنید نسخه جدید KoboldCpp رو قرار بدین... چون از CLBLAST پشتیبانی میکنه که برنامه های دیگه این قابلیتو ندارن
//این کامنتو گذاشته بودم جواب ندادید 😢
Qwen3.6-27B-UD-Q4_K_M لطفاااااا (اگرم لطف میکنین آنسنسورد میذارین ورژن heretic رو بذارین بجای hauhau چون اون kl-div کمتری نسبت به اینیکی داره و به مدل اوریجینال رفتارو هوش و غیرهاش نزدیکتره)
Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P - در 5 پارت همین الان روی صفحه امروز اپدیت شده. هر روز صفحه رو چک کنید. منتهیHauhauCS. این لینک بذارید بهتره بچه ها
لطفا مدل 3bit رو بزارید ممنونم. 🙏🌸
سلام دوباره وقت بخیر. Unsloth ی مدل mlx هم برای macbook گذاشته ممنون میشم اونم آپلود کنید. اینجاست لینکش:
https://unsloth.ai/docs/models/qwen3.6
لطفا Qwen3.6-35B-A3B MLX مدل 4bit رو بزارید ممنونم. 🙏🌸
شایدبراتون جالب باشه اخرین train کوئن 14b که قبلا گذاشته بودین اکتبر2024 بوده....و اخرین train جما Q8-0 که ضعیفترین وکم حجم ترین مدل بود ژانویه 2025 بوده.با سپاس از وقت و تلاشی که میکنید.
لطفا q2 رو هم آپلود کنین ممنونم از لطف شما
آدرس تو دانلود رو نمیده، پنجره زود بسته میشه!!
بزنید در دانلود منیجر- به خاطر قطعی هاست.
عرض ادب. چرا این مدل(مدل Qwen3.6-35B-A3B-UD-IQ3_XXS - پارت 1) دانلود نمیشه؟ میزنم رو دانلود یه صفحه یک ثانیه ای باز میشه بعد هیچی...
سلام. دانلود میشه با اینترنت دانلود منیجر تست کنید.
سلام و عرض ادب. من سیستمم ضعیفه، کور ای 5 نسل 5 و گرافیک 2 و رم 16. کدوم مدل رو میتونم نصب کنم؟ ممنون از سایت بیت گرف که عالیه
سلام یه روش نه علمی ولی خب ساده اینه که مجموع رم گرافیک و سیستم باید از حجم مدلتون بالاتر باشه
تو دیدگاه قبل یادم رفت منابع مصرفی رو اشاره کنم. برای کانتکست حدود 128K و نسخه Q4_K_M روی llama-server و کارکردن با Cline+VSCode:
vram=10.8GB
shared=14.4GB
کل رم مصرفی سیستم (ویندوز ۱۱)=۲۹.۶GB
یعنی با RTX 3060 12GB و ۳۲ گیگ رم میشه راحت ازش استفاده کرد.
سه مدل qwen3.6 35b رو من امتحان کردم:
Qwen3.6-35B-A3B-UD-IQ2-M
Qwen3.6-35B-A3B-UD-IQ3_XXS
Qwen3.6-35B-A3B-UD-Q4_K_M
سختافزار سیستم هم این بود:
i5 9400f
48GB DDR4
RTX 3060 12GB
نکته جالبش اینه که هر سه مدل در سطح قابلقبول و بعضا خوبی از لحاظ سرعت کار میکردن. البته که نسخه Q4_K_M رو نگه داشتم چون دو مورد دیگه برا برنامهنویسی بعضا گیج میشدن یا خطا میدادن. البته نه اینکه قابل استفاده نباشن ولی خب مثلا وقتی ترکیب افزونه Cline و VSCode رو برای برنامهنویسی استفاده میکنی، مدلهای دیگه هر از گاه خطای خروجی ناقص میدادن و البته کدهاشون هم معمولا دارای باگ بود که باید مدتی توسط خود اجنت روش کار میشد که وقتگیرتر بود. نسخه Q4_K_M خیلی مطمئنتر کار میکنه.
عملکرد هم بد نیست. تو llama.cpp و اجرای سرور که به نظرم مهمتر از بنچمارک گرفتن با llama-bench یا حتی پرامپتهای شخصی هست، من با کانتکست حدود 128K تا ۲۳ الی ۲۵ توکن بر ثانیه خروجی گرفتم و پردازش پرامپت هم در حدود ۳۰۰ الی ۳۵۰ توکن بر ثانیه بود. البته ممکنه کار خیلی سنگین بشه افت داشته باشه ولی ندیدم زیر ۱۵ توکن بر ثانیه بیاد که همچنان خوبه.
من با 256K کانتکست هم امتحان کردم و جالبه که بدون مشکل خاصی کار میکرد 🤪
خواستین gemma-4-26B-A4B-it-UD-Q3_K_M رو هم امتحان کنین. از لحاظ سرعت تو مایههای نسخه Q4_K_M کار میکنه و کدهای تمیز و با باگ کمی تولید میکنه هرچند کارش تو UI تعریفی نداره ولی خب بازی Space Invader رو تو یه تلاش (VSCode+Cline) خیلی تمیز و خوشگل دراورد.
به این میگن تلاشی که باید تشکر کرد. دم شما گرم بابت کامنت خوبتون. به دیگر کاربران کمک میکنه
واقعا کارتون درسته میخواستم ی جوری دانلودش کنم خیلی سخت بود. همون روزای اول شما گذاشتید. :namaste:
چند روزه Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ4_NL.ggufو دارم و با openclaw و lmstudio ازش استفاده میکنم الان میخوام مدل Qwen3.6-35B-A3B-UD-Q4_K_M و دانلود کنم. آیا این همون مدل unsloth هست؟
خیلی ممنونم ازتون واقعا درجه یکید. :one:
سلام خواهش میکنم. بله UD = Unsloth
سلام وقت بخیر
تفاوت مدل هایی که برای qwen 3.6 گذاشتید رو میشه توضیح بدید؟
من نمیدونم کدوم رو بهتره که دانلود کنم
سیستمم Mac M4 و رم 16 هست
سلام به زبان ساده مدلها معمولا فشرده می شوند مثلا از Q1 تا Q8. وقتی به حجمشون نگاه میکنی فرضا Q4 = 20 گیگ هست. یعنی شما مجموع گرافیک و رم سیستم تان باید بیشتر از 20 گیگ باشد. هرچه به سمت کیو یک می روید کیفیت کمتر (پاسخ دهی) ولی سیستم ضعیف تری هم میتونه ران کنه. هرچه به سمت کیو 8 میرید سیستم سنگین تری میطلبه و کیفیت پاسخ گویی میره بالاتر
دوستان شدیدا توصیه میشه حجمتون رو روی IQ1_M دور نریزید
این مدل فشرده ترین ورژن ممکنه که بیشتر جنبه آزمایشی و تست داره و خیلی وقتا تو جمله سازی هم به مشکل میخوره
و به نویسنده های محترم سایت هم توصیه میشه بعد از مصرف مواد فایل آپلود نکنن.
وزن پایینتر = فشردگی بیشتر = کیفیت پایینتر
سلام لطفا Qwen3.6-27B در وزن های Q4_K_M یا IQ4_NL قرار بدید
ممنون
سلام وقتتون بخیر ممنون برای اپدیت فایل های مورد نیاز این مدل
فقط یک سوال داشتم این فایل ویژنی که گذاشتید فایل ویژن mmproj-F16.gguf قابل استفاده هست برای این نسخه Qwen3.6-35B-A3B-UD-IQ3_XXS ؟
با تشکر از سایت خوبتون واقعا
سلام بله قابل استفاده است.
سلام لینک ها کار نمیکنن
مجدد تست شد کار میکنه. لطفا کش مرورگر تون رو کامل پاک کنید و سپس هارد ریلود کنید و تست کنید. از اینترنت دانلود منیجر هم استفاده کنید. ctrl + shift +r برای هارد ریلود.
از سایت بیتگرف صمیمانه تشکر میکنم. در شرایطی که دسترسی به منابع معتبر سخت شده، وجود پلتفرمی امن و قابل اعتماد مثل بیتگرف واقعاً ارزشمنده. اینکه محتوای بهروز و کاربردی رو بهصورت رایگان در اختیار همه قرار میدید جای قدردانی داره.
سلام و ممنون بابت انرژی که به ما میدید.
درود. ارسطو جان سپاسگزارم که مشکل رو حل کردید, qwen 3.6 27B q4 هم قرار بدین دیگه فوقالعاده میشه. ممنون
سلام وقتتون بخیر در صورت امکان ممنون میشم نسخه های متفاوت رو هم قرار بدید و اینکه لینک های دانلود ارور 403 میده لطفا بررسی کنید با تشکر از سایت خوبتون
خطا برطرف شده . سعی میکنیم وزن های پایینتر رو هم قرار بدیم.
با سلام . متاسفانه لینک های دانلود کار نمیکنن.
You don't have permission to access this resource.Server unable to read htaccess file, denying access to be safe
اگر میشه یه بررسی کنین.
خیلی ممنون
سلام مشکل برطرف شد به خاطر وضعیت شبکه و عدم امکان تمدید ssl بود.
سلام خسته نباشید
لطفا ud نسخه 27b رو قرار بدید
اگه امکانش هست https://github.com/likelovewant/ollama-for-amd/releases آخرین ریلیزش رو هم بذارین واسه amd
ممنون
سلام وقتی میزنم روی دانلود این خطا رو میده درستش کنید
Forbidden
You don't have permission to access this resource.Server unable to read htaccess file, denying access to be safe
در حال پیگیری هستیم احتمالا تا ساعاتی دیگر حل شود. مشکل ssl رو به سختی داریم حل میکنیم با توجه به شرایط
نسخه کم حجم ترش رو نمیزارید؟
چرا بزودی اوایل هفته قرار میدیم.
Q4 منظورم بود که جا شه تو سیستم qwen3.6 27B Q4 k m ممنوووووووون
درود.
اولا اینکه واقعا دستتون درد نکنه. خیلی زحمت میکشید. مرسییییی.
دوم اینکه دیدم میگین درخواست داریم بگیم
دوتا درخواست دارم.
درخواست۱) همین مدل qwen3.6 27B Dense رو داد چند ساعت پیش همین ورژن کوانتیزه شده gguf رو برای اون هم اگه میشه قرار بدین. Q8
درخواست۲) برای کم که رو لینوکس رد هت (راکی ۹) هستم یه چیز headless میخوام lm studio ارور یکی از داینامیک لایبرری ها رو میده libatk-1.0.so.0 یه همچین چیزی دقیق یادم نیست. میخواستم ببینم چیزی مثل llamacpp kobold cpp اینا داریم که endpoint api بدن بعد اونور یه کانتینر داکری چیزی ollama بیاریم بالا و وصل شیم به مدل؟ من خیلی وارد نیستم ولی فکر کردم این دوتا رو بهتون بگم چون گیر کردم الان وزن مدل رو دارم ولی lmstudio اپ ایمیجش رو ران میکنم ارور لایبرری میده اینترنتم نیست ادم بگرده نصب کنه.
سپاسگزارم.
سلام ممنون از مقاله
خود مدلی که برای دانلود هست تست شده؟
چون توی اجراش به مشکل خوردم
ممنون میشم وزن های پایین تر رو هم قرار بدید
با ۲۴ ساعت اختلاف تست شد متاسفانه هدر فایل از طرف سازنده مشکل داشته و ما چون خیلی سریع منتشر کرده بودیم نسخه با باگ بوده. نسخه جدید اصلاح شد و نسخه بهینه قرار گرفت.
لطفا اگر امکانشو داشتید abliterated رو هم بگزارید
و اینکه خیلی دنبال این مدل بودم. خیلی ممنون!