


در این مقاله میخواهیم به معرفی استیبل دیفیوژن 3 و بررسی ویژگیهای جدید این هوش مصنوعی بپردازیم. البته که این ورژن از هوش مصنوعی استیبل دیفیوژن هنوز به صورت عمومی انتشار پیدا نکرده و فقط میتوان برای استفاده از نسخه اولیه آن از طریق سایت stability.ai ثبتنام کرده و منتظر دریافت لینک دعوت باشیم، این نسخه اولیه برای پیدا کردن باگها و مشکلاتی که وجود دارد و همچنین بازخوردهای کاربرها ارائه میشود تا بعد از آن با رفع تمام این مشکلات، نسخه اصلی استیبل دیفیوژن 3 به صورت عمومی منتشر شود. در ادامه به بررسی ویژگیهایی که در این نسخه از استیبل دیفیوژن وجود دارد، میپردازیم. ولی در ابتدا پیشنهاد میکنیم که با مطالعه مقاله نصب استیبل دیفیوژن در 7 مرحله، به نصب این هوش مصنوعی قدرتمند پرداخته و مسیر جدیدی را در حرفه خود شروع کنید.
استیبل دیفیوژن 3 چیست
Stable Diffusion 3 آخرین نسل از مدلهای متن به تصویر (txt2image) هوش مصنوعی است که توسط کمپانی Stability AI منتشر شده است. البته که پیشتر اشاره کردیم که این هوش مصنوعی هنوز به طور عمومی در دسترس نیست ولی به زودی شاهد انتشار آن خواهیم بود.
این یک مدل واحد نیست، بلکه یک خانواده از مدلها است که از 800میلیون تا 8بیلیون پارامتر یا دیتا را شامل میشود. به عبارت دیگر، کوچکترین مدل استیبل دیفیوژن 3 کمی کوچکتر از stable diffusion 1.5 (1 بیلیون داده) است و بزرگترین مدل کمی بزرگتر از مدل stable diffusion XL (حداقل 6.6 بیلیون داده + بهبود عملکرد) است.
بهبودهای عملکردی در استیبل دیفیوژن 3
حالا باید ببینیم که در نسخه Stable Diffusion 3 چه چیزهایی تغییر کرده و چه بهبودهایی را از این نسخه باید انتظار داشته باشیم. طبق صحبتهای خود کمپانی stability ai، استیبل دیفیوژن 3 در قسمتهای زیر بهبود پیدا کرده است:
بهتر شدن جنریت متن
مدت زمان زیادی است که تولید متن و حروف برای استیبل دیفیوژن یک ضعف محسوب میشود، مخصوصا در مدلهای sd 1.5. البته این موضوع درStable Diffusion XL و Stable Cascade به طور قابل توجهی بهبود پیدا کرده است، با این حال باز هم این هوش مصنوعی در جنریت متنهای بلند، دچار ضعفهایی از جمله جا انداختن حروف، ناخوانایی و فونتهای نازیبا و… است.
این موضوع در استیبل دیفیوژن 3 بهطور قابل توجهی پیشرفت کرده است و ما شاهد جنریت فوقالعاده متن هستیم. این نسخه از استیبل دیفیوژن با جملات طولانی هم مشکلی ندارد و از فونتهای زیبایی استفاده میکند و تایپوگرافی آن بینظیر است.

پیروی بهتر از پرامپت
یک مشکل برجسته در SDXL و Stable Cascade این است که آنها از دستورات به خوبی DALLE 3 پیروی نمیکنند. یکی از نوآوری های DALLE 3 استفاده از زیرنویسهای تصویر بسیار دقیق در آموزش برای یادگیری پیروی از دستورات است.
از قبل به این موضوع فکر کرده بودیم که نسخه جدید Stable Diffusion میتواند از همین روش برای بهبود مدل استفاده کند. و الان متوجه شدیم که آنها این کار را در SD 3 انجام دادهاند.
Stable Diffusion 3 باید حداقل به خوبی DALLE 3 در پیروی از پرامپت باشد و این موضوع بسیار هیجانانگیز است.

سرعت و عملکرد در سیستمهای شخصی
اگر کارت گرافیکی با 24 گیگابایت رم داشته باشید، میتوانید بزرگترین مدل SD3 را به صورت محلی بر روی سیستم خود اجرا کنید. این نیاز احتمالاً پس از انتشار، کاهش مییابد و توسعهدهندگان شروع به انجام انواع بهینهسازی برای کامپیوترهای شخصی کرده و مدلهایی را عرضه میکنند که با کارتگرافیکهای پایینتر هم قابل اجرا باشند.
پیشبینی اولیه 34 ثانیه برای یک تصویر 1024×1024 در کارت گرافیک RTX 4090 (50 step) است. احتمالا این موضوع در هنگام انتشار عمومی پیشرفت بیشتری کند.

امنیت در استیبل دیفیوژن 3
مشابه مدل های جدیدتر Stable Diffusion، Stable Diffusion 3 احتمالا فقط تصاویری که مشکلات امنیتی ندارند را تولید میکند. علاوه بر این، هنرمندانی که نمیخواستند کارشان در مدلها باشد، میتوانستند انصراف دهند. در حالی که این امر باعث میشد تا سبکهای موجود برای ترکیب و تطبیق کاهش پیدا کند، بنابراین باید در مدلهای جدید، امنیت را طوری تنظیم کرد که از مدلها استفادههای نادرست نشود.
البته هنوز نمیدانیم که سازندگان استیبل دیفیوژن 3 در مقابله با تصاویر جعلی و سواستفاده از این تصاویر چه رویهای را میخواهند در پیش بگیرند. میتوان گفت تصاویر ساختگی از افراد مشهور بیشترین آسیب را در انتشار اطلاعات نادرست وارد میکند. DALLE 3 به دلیل این که در تولید تصاویر رئال خوب نیست، از این دردسر دوری کرده است. ولی Stable Diffusion در جنریت تصاویر فوتورئالیستی بسیار خوب عمل کرده است. امیدواریم برای جلوگیری از این سواستفادهها از موضوع رئال بودن، دور نشود.
ویژگیهای جدید استیبل دیفیوژن 3
در این قسمت ویژگیهای جدید استیبل دیفیوژن 3 در مقابله با نسخههای دیگر استیبل دیفیوژن را با هم بررسی میکنیم.
ویژگی اول: پیشبینیکننده نویز
یک تغییر قابل توجه در Stable Diffusion 3 انحراف از معماری پیشبینیکننده نویز U-Net است که در Stable Diffusion 1 و 2 استفاده میشود.
Stable Diffusion 3با بهکارگیری ترانسفورماتورهای دیفیوژن بهجای معماری U-Net در نسخههای قبلی، گامی بزرگ در جهت ارتقای کیفیت تصاویر خروجی برداشته است. این تغییر مزایای قابلتوجهی را به ارمغان میآورد، از جمله:
درک عمیقتر از متن:
ترانسفورماتورهای دیفیوژن قادر به تجزیه و تحلیل دقیقتر متن ورودی هستند. بهعبارتدیگر، آنها میتوانند مفاهیم پیچیدهتر و ظرافتهای زبانی را درک کنند و به مدل هوش مصنوعی اجازه میدهند تا تصاویر خروجی را با دقت و ظرافت بیشتری با متن مطابقت دهد.
کنترل بیشتر بر تصاویر خروجی:
با استفاده از ترانسفورماتورهای دیفیوژن، کاربر کنترل بیشتری بر جزئیات و ویژگیهای مختلف تصویر نهایی خواهد داشت. این امر به دلیل توانایی این ترانسفورماتورها در تمایز دقیقتر بین ویژگیهای بصری مختلف تصویر است.
خلاقیت و تنوع بیشتر:
ترانسفورماتورهای دیفیوژن به دلیل درک عمیقتر از متن و تصاویر، قادر به تولید تصاویر خلاقانهتر و متنوعتر هستند. این امر به مدل اجازه میدهد تا ایدههای جدید و منحصر به فرد را از متن استخراج کند و تصاویر خروجی را به سبکهای مختلف هنری و بصری ارائه دهد.
مقیاسبندی و ارتقای آسان:
معماری مبتنی بر ترانسفورماتور دیفیوژن قابلیت مقیاسبندی آسان را فراهم میکند. بهعبارتدیگر، با افزایش تعداد لایهها و پارامترها در مدل، میتوان به طور قابلتوجهی کیفیت تصاویر خروجی را ارتقا داد. این امر مسیری روشن برای پیشرفت و ارتقای مداوم Stable Diffusion 3 در آینده ترسیم میکند.
مثال:
فرض کنید کاربر میخواهد تصویری از یک “منظره کوهستانی با دریاچهای در وسط” را با استفاده از Stable Diffusion 3 تولید کند.
با U-Net: ممکن است تصویری با جزئیات دقیق از کوهها و درختان ارائه دهد، اما ممکن است در انسجام کلی تصویر و تناسب بین عناصر مختلف آن مشکل داشته باشد.
با ترانسفورماتورهای دیفیوژن: ترانسفورماتورهای دیفیوژن قادر به درک مفاهیمی مانند “منظره” و “دریاچه” هستند و میتوانند تصویری با انسجام کلی بیشتر و تناسب مناسب بین کوهها، درختان و دریاچه ایجاد کنند.
علاوه بر این ترانسفورماتورهای دیفیوژن میتوانند از اطلاعات بصری موجود در دنیای واقعی برای ارتقای کیفیت تصاویر خروجی استفاده کنند. این ترانسفورماتورها پتانسیل بالایی برای کاربرد در زمینههای مختلف مانند طراحی گرافیک، انیمیشن، و بازیهای کامپیوتری دارند.
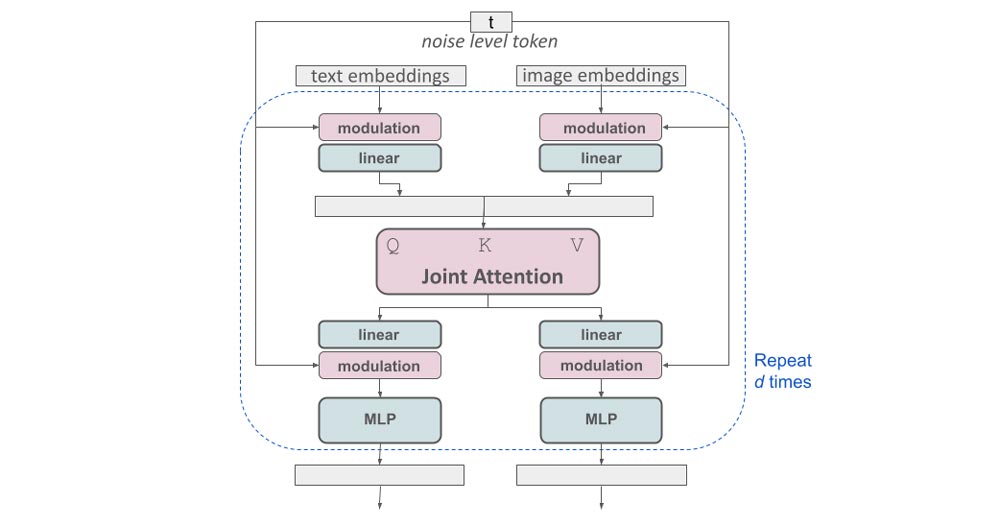
این بلوک ساختار جالبی دارد که دستورات متن و تصویر نهفته در آن را در یک نقطه قرار میدهد. به نظر میرسد این معماری برای اضافه کردن شرایط چند وجهی، موقعیت خوبی دارد و میتواند به خوبی نویزها را کنترل کرده و از “هیچ”، تصاویر خارقالعاده تولید کند.
ویژگی دوم: Sampling method
تیم stability تلاش قابل توجهی را صرف مطالعه sampling methodها کرده است تا آن را سریع و باکیفیتتر کند. Stable Diffusion 3 از سمپلینگ متد Retified Flow استفاده میکند. اساسا، این یک مسیر مستقیم از تبدیل نویز به یک تصویر واضح است، در واقع این sampling method سریعترین مسیر برای جنریت تصاویر است.
خب، به نظر میرسد که sampling methodها کاملاً متفاوت خواهند شد. ولی با توجه به تجربهای که به دست آوردیم، برخی از sampling methodهای موجود هم به اندازه کافی خوب هستند، باید دید که با توجه به رویهای که stability ai در پیش گرفته است، کیفیت آنها در آینده چه تغییراتی میکند.
ویژگی سوم: کدگذاری متون
Stable Diffusion 1 از یک کدگذار متن به نام CLIP استفاده میکند، در حالی که Stable Diffusion XL از دو کدگذار به نام های CLIP و OpenCLIP استفاده میکند. این تفاوت در تعداد کدگذارها، بر عملکرد و کیفیت تصاویر خروجی هر دو مدل تاثیر میگذارد.
وظایف کدگذار متن
- تجزیه و تحلیل متن: کدگذار متن، عبارات و دستورات کاربر را به برداری از اعداد تبدیل میکند که مدل هوش مصنوعی میتواند آن را درک کند.
- ایجاد ارتباط بین متن و تصویر: کدگذار متن، ارتباط بین مفاهیم و ایدههای موجود در متن و ویژگیهای بصری تصویر را برقرار میکند.
مزیت استفاده از دو کدگذار در Stable Diffusion XL
- دقت و درک بهتر متن: با استفاده از دو کدگذار، مدل میتواند متن را با دقت و ظرافت بیشتری تجزیه و تحلیل کند و به مفاهیم و ایدههای پیچیدهتر پی ببرد.
- کنترل بیشتر بر تصاویر خروجی: دو کدگذار به مدل اجازه میدهد تا به طور دقیقتر بین ویژگیهای بصری مختلف تصویر تمایز قائل شود و به کاربر کنترل بیشتری بر جزئیات تصویر نهایی ارائه دهد.
- ایجاد تصاویر خلاقانه تر: با استفاده از دو کدگذار، مدل میتواند ایدههای خلاقانهتری را از متن استخراج کند و تصاویر منحصر به فرد و جالبی را تولید کند.
محدودیت های استفاده از دو کدگذار
- نیاز به منابع محاسباتی بیشتر: استفاده از دو کدگذار، به قدرت محاسباتی بیشتری نیاز دارد و ممکن است سرعت پردازش را کاهش دهد.
- پیچیدگی بیشتر: استفاده از دو کدگذار، مدل را پیچیدهتر میکند و ممکن است استفاده از آن برای کاربران مبتدی دشوارتر باشد.
در نهایت انتخاب بین Stable Diffusion 1 و Stable Diffusion XL به نیازهای شما بستگی دارد. اگر به دنبال تصاویر با کیفیت و خلاقانه هستید و به قدرت محاسباتی کافی دسترسی دارید، Stable Diffusion XL گزینه مناسبتری است. اما اگر به دنبال یک مدل سادهتر و سریعتر هستید، Stable Diffusion 1 میتواند انتخاب بهتری باشد.
تمام این مباحث کدگذاری را بررسی کردیم تا به اینجا برسیم که یکی از ویژگیهای جدید Stable Diffusion 3 استفاده از 3 کدگذار است.
- OpenAI’s CLIP L/14
- OpenCLIP bigG/14
- T5-v1.1-XXL
آخرین مورد بسیار حجیم و پیچیده است و اگر متنی تولید نمیکنید میتوانید آن را حذف کنید. حذف T5 برای استنتاج، تنها منجر به کاهش قابلتوجه عملکرد در هنگام ارائه درخواستهای بسیار پیچیده که شامل جزئیات زیادی یا مقادیر زیادی متن نوشته شده است، میشود. شکل پایین سه نمونه تصادفی را در هر نمونه نشان میدهد.

ویژگی چهارم: کپشننویسی بهتر
یکی از کارهایی که DALLE 3 انجام داد، استفاده از زیرنویسها یا همان کپشنهای بسیار دقیق در آموزش این هوش مصنوعی بود. به همین دلیل است که DALLE 3 به خوبی از دستور پیروی میکند. تیم سازندگان Stable Diffusion 3 نیز این کار را انجام دادهاند. بنابراین میتوانید انتظار پیروی کردن سریع و راحت پرامپت، مانند DALLE 3 را داشته باشید.

در این مقاله به بررسی ویژگیهای استیبل دیفیوژن 3 پرداختیم. البته که این نسخه از استیبل دیفیوژن هنوز در دسترس عموم نیست و فقط با ثبتنام میتوانید از نسخه اولیه آن استفاده کنید. با توجه به موضوعات مختلفی که در این مقاله بررسی کردیم، متوجه شدیم که بهبود عملکرد این نسخه، بسیار فوقالعاده بوده است و همچنین ویژگیهای جدیدی که به استیبل دیفیوژن 3 اضافه شده است، باعث شده تا خروجیهای باکیفیتتری را در زمان کمتر جنریت کنیم.



















