

در این مقاله میخواهیم به معرفی هوش مصنوعی stable audio 2.0 که یک هوش مصنوعی رایگان برای تولید آهنگهای بدون کپی رایت است، بپردازیم. حتما شما هم تا به حال در پیدا کردن آهنگ برای تیزر، ویدیوهای یوتیوب، تیکتاک، اینستاگرام و… دچار مشکل شدهاید. اینبار میخواهیم به موضوع آهنگسازی با هوش مصنوعی stable audio 2.0 بپردازیم.
امروزه با پیشرفت روزافزون تکنولوژی، شاهد افزایش هوشهای مصنوعی با کاربریهای متفاوت هستیم. یکی از کمپانیهایی که در این عرصه بهطور پیشتاز عمل کرده است، شرکت stability ai است. حتما تا به حال نام استیبل دیفیوژن به گوشتان خورده است، استیبل دیفیوژن قدرتمندترین هوش مصنوعی در عرصه ساخت و ادیت عکس و ویدیو و انیمیشن میباشد. حالا ما شاهد این هستیم که کمپانی stability ai در عرصه تولید آهنگ هم دست به کار شده و هوش مصنوعی stable audio را معرفی کرده است. در ادامه میخواهیم به معرفی این هوش مصنوعی رایگان پرداخته و ویژگیهای آن را باهم بررسی کنیم.
معرفی هوش مصنوعی stable audio 2.0
Stable Audio یک ابزار هوش مصنوعی مبتنی بر متن است که به شما امکان میدهد آهنگهای کوتاه بسازید. این ابزار توسط Stability AI، یک شرکت تحقیقاتی هوش مصنوعی که به خاطر مدلهای Stable Diffusion و Disco Diffusion خود شناخته شده است، در سپتامبر 2023 رونمایی شد. این هوش مصنوعی در ابتدا قادر به تولید یک آهنگ با مدت زمان حداکثر 90 ثانیه بود. ولی کمپانی stability ai در مارچ 2024، از نسخه دوم این هوش مصنوعی یعنی stable audio 2.0 رونمایی کرد، این هوش مصنوعی قادر است تا آهنگهایی با مدت زمان حداکثر 3 دقیقه تولید کند.
جدیدترین مدل صوتی stability ai با قابلیتهای جدیدش جعبه ابزار خلاقیت هنرمندان و موسیقیدانان را گسترش میدهد. با استفاده از دستورات متن به صدا و صدا به صدا، کاربران میتوانند ملودیها، قطعههای پشتیبان، استمها و جلوههای صوتی بسازند و بدین ترتیب، فرآیند خلاقیت را بهبود بخشند.
در اینجا قسمتی از مقالهای که توسط کمپانی stability ai منتشر شده است را باهم میخوانیم:
“امروز، با معرفی Stable Audio 2.0 بسیار خوشحالیم. این مدل با استفاده از یک عبارت با زبان طبیعی، امکان تولید آهنگهای کامل با کیفیت بالا، ساختار موسیقی منسجم و حداکثر با مدت زمان سه دقیقه و با فرکانس ۴۴.۱ کیلوهرتز در حالت استریو را فراهم میکند. مدل جدید فراتر از متن به صدا عمل میکند و قابلیتهای صدا به صدا را نیز ارائه می دهد. کاربران اکنون میتوانند نمونههای صوتی را آپلود کرده و از طریق عبارات با زبان طبیعی، آنها را به گسترهی وسیعی از صداها تبدیل کنند. این بهروزرسانی همچنین با گسترش تولید جلوههای صوتی و انتقال سبک، انعطافپذیری، کنترل و فرایند خلاقانهی پیشرفتهتری را برای هنرمندان و موسیقیدانان فراهم میکند.
Stable Audio 2.0 بر اساس Stable Audio 1.0 ساخته شده است که در سپتامبر ۲۰۲۳ به عنوان اولین ابزار تولید موسیقی هوش مصنوعی با قابلیت تجاری و توانایی تولید موسیقی با کیفیت بالا ۴۴.۱ کیلوهرتز با استفاده از تکنولوژی توزیع پنهان، معرفی شد. این ابزار از آن زمان به عنوان یکی از بهترین اختراعات ۲۰۲۳ مجلهی تایم شناخته شده است. این مدل جدید هماکنون به صورت رایگان در وبسایت Stable Audio قابل استفاده است و به زودی از طریق درگاه برنامهنویسی کاربردی Stable Audio در دسترس خواهد بود.”
نحوه عملکرد stable audio
Stable Audio از یک مدل زبانی بزرگ (LLM) برای تبدیل متن به موسیقی استفاده میکند. LLM بر روی مجموعه دادههای عظیمی از متن و موسیقی آموزش دیده است. این به LLM اجازه میدهد تا الگوهای بین متن و موسیقی را یاد بگیرد و از این الگوها برای تولید موسیقی جدید بر اساس متن ارائهشده توسط کاربر استفاده کند.
البته در نسخه جدید Stable Audio 2.0 برای تبدیل ایدهها به نمونههای کاملا ساخته شده، امکان آپلود فایلهای صوتی فراهم شده است. شرایط و قوانین این کمپانی، الزام میکند که فایلهای آپلود شده بدون حق کپی رایت باشند. این هوش مصنوعی برای حفظ انطباق با این قوانین و جلوگیری از نقض حق کپی رایت، از سیستم تشخیص پیشرفته محتوا استفاده میکند.
قابلیتهای stable audio 2.0
ویژگی اول: Stable audio 2.0 استاندارد جدیدی را در صدای تولید شده توسط هوش مصنوعی تعیین میکند و قادر است تا آهنگهای با کیفیت بالا و کامل با ساختار موسیقی منسجم را با مدت زمان حداکثر 3 دقیقه و با فرکانس 44.1 کیلوهرتز، در حالت استریو تولید کند.
ویژگی دوم: این مدل جدید قابلیت تولید صدا از صدا را معرفی می کند که به کاربران امکان میدهد با استفاده از متن (عبارات طبیعی) نمونههایی را بارگذاری و آنها را تغییر دهند.
ویژگی سوم: stable audio میتواند آهنگهایی در ژانرهای مختلف مانند پاپ، راک، الکترونیک، کلاسیک و غیره تولید کند.
ویژگی چهارم: Stable Audio به شما امکان میدهد تنظیمات مختلفی مانند سرعت، گام، تونالیته و سازها را تنظیم کنید.
ویژگی پنجم: Stable Audio دارای رابط کاربری سادهای است که استفاده از آن را برای هر کسی آسان میکند.
ویژگی ششم: این مدل با توانایی ساخت صدا و جلوههای صوتی متنوع، از تایپ کردن روی کیبورد گرفته تا غرش جمعیت یا همهمه خیابانهای شهر، روشهای جدیدی برای ارتقای پروژههای صوتی ارائه میدهد.
ویژگی هفتم: این ویژگی جدید، صدای ساختهشده یا آپلود شدهی شما را در طی فرآیند تولید به طور یکپارچه تغییر میدهد. این قابلیت امکان سفارشیسازی تم خروجی را برای مطابقت با سبک و لحن خاص پروژه شما فراهم میکند.
در این قسمت، چند نمونه از آهنگهایی که با هوش مصنوعی stable audio 2.0 ساخته شده است را به همراه پرامپتی که به آن دادهایم مشاهده میکنید:
Prompt: Energizing and exciting music for an advertising teaser, car advertising teaser, high speed indicator, technology, beautiful, beat, beautiful peaks and valleys in the rhythm
Prompt: Solo violin playing, with a frequency of 963 Hz, soulful, relaxing, suitable for meditation
Prompt: A song for a children’s cartoon for ages 5 to 8, childish, happy, use guitar, violin, drum, organ, beautiful, pop, use the sound effects of children’s laughter, the noise of children
شما میتوانید همین الان از طریق لینک وبسایت Stable audio به طور رایگان از این هوش مصنوعی استفاده کنید.
معماری مدل توزیع پنهان Stable Audio 2.0
معماری مدل توزیع پنهان Stable Audio 2.0 به طور خاص برای تولید قطعههای کامل با ساختارهای منسجم طراحی شده است. برای دستیابی به این هدف، همه اجزای سیستم را برای عملکرد بهتر در بازههای زمانی طولانیتر تطبیق دادهاند. یک رمزگذار خودکار (autoencoder) بسیار فشرده، شکل موج صدای خام را به نمایههای بسیار کوتاهتری فشرده میکند. برای مدل توزیع، به جای U-Net قبلی، از یک توزیعگر تبدیلی (diffusion transformer – DiT) مشابه آنچه در Stable Diffusion 3 استفاده میشود، استفاده میکنند، زیرا در دستکاری دادهها روی توالیهای طولانی توانمندتر است. ترکیب این دو عنصر منجر به مدلی میشود که قادر به شناسایی و بازتولید ساختارهای بزرگمقیاس است که برای آهنگسازی باکیفیت ضروری هستند.
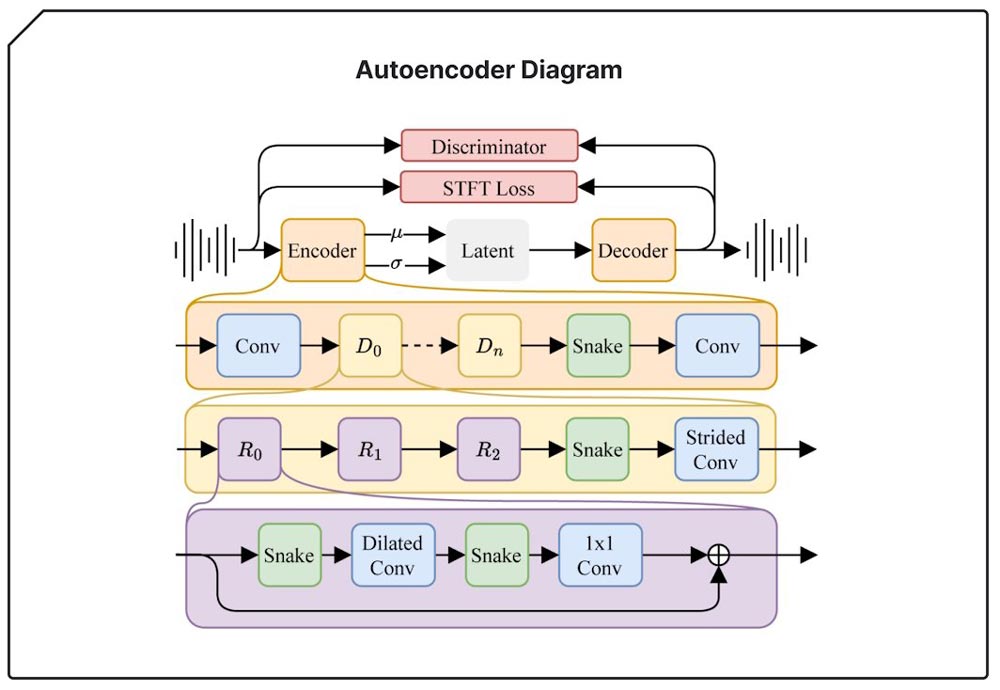
رمزگذار خودکار، صدا را فشرده کرده و سپس آن را به حالت اصلی باز میگرداند. این کار با گرفتن ویژگیهای ضروری صدا و بازتولید آنها در حالی که جزئیات کماهمیتتر را فیلتر میکند، برای دستیابی به تولیدات منسجمتر انجام میشود.
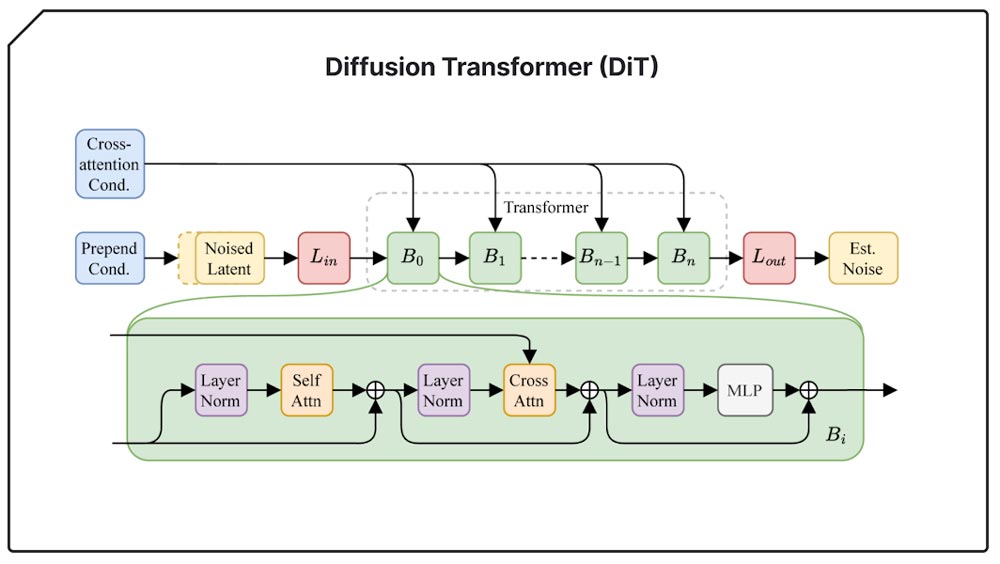
توزیعگر تبدیلی (Diffusion Transformer – DiT) به طور افزایشی نویز تصادفی را به دادهی ساختارمند تبدیل میکند، در این فرآیند الگوها و روابط پیچیده را شناسایی میکند. با ترکیب شدن با رمزگذار خودکار، قابلیت پردازش توالیهای طولانیتر را به دست میآورد تا تفسیر عمیقتر و دقیقتری از ورودیها ایجاد کند.
تدابیر امنیتی
مشابه مدل ۱.۰، مدل ۲.۰ نیز روی دادههایی از AudioSparx آموزش داده شده است که شامل بیش از ۸۰۰،۰۰۰ فایل صوتی حاوی موسیقی، جلوههای صوتی و استمهای تکساز، به همراه توضیحات متنی مربوطه است. به تمام هنرمندان AudioSparx این امکان داده شده است که از آموزش مدل Stable Audio انصراف دهند.
برای محافظت از حق تکثیر سازندگان، برای آپلودهای صوتی، کمپانی stability ai با Audible Magic همکاری میکند تا از فناوری تشخیص محتوای آنها (ACR) برای قدرت بخشیدن به مطابقت محتوای لحظهای به منظور جلوگیری از نقض حق تکثیر استفاده کنند.
در این مقاله به معرفی هوش مصنوعی stable audio 2.0 و همچنین ویژگیهای آن پرداختیم. با توجه به امکاناتی که کمپانی stability ai در این هوش مصنوعی قرار داده است، میتوان آینده آهنگسازی با هوش مصنوعی را نیز روشن دید و از آن برای ساخت آهنگهای حداکثر 3 دقیقهای برای یوتیوب، تیکتاک، اینستاگرام، تیزر، اینترو و… استفاده کرد، حتی هنرمندان و آهنگسازان نیز میتوانند از این ابزار برای گرفتن ایده، استفاده کنند.















